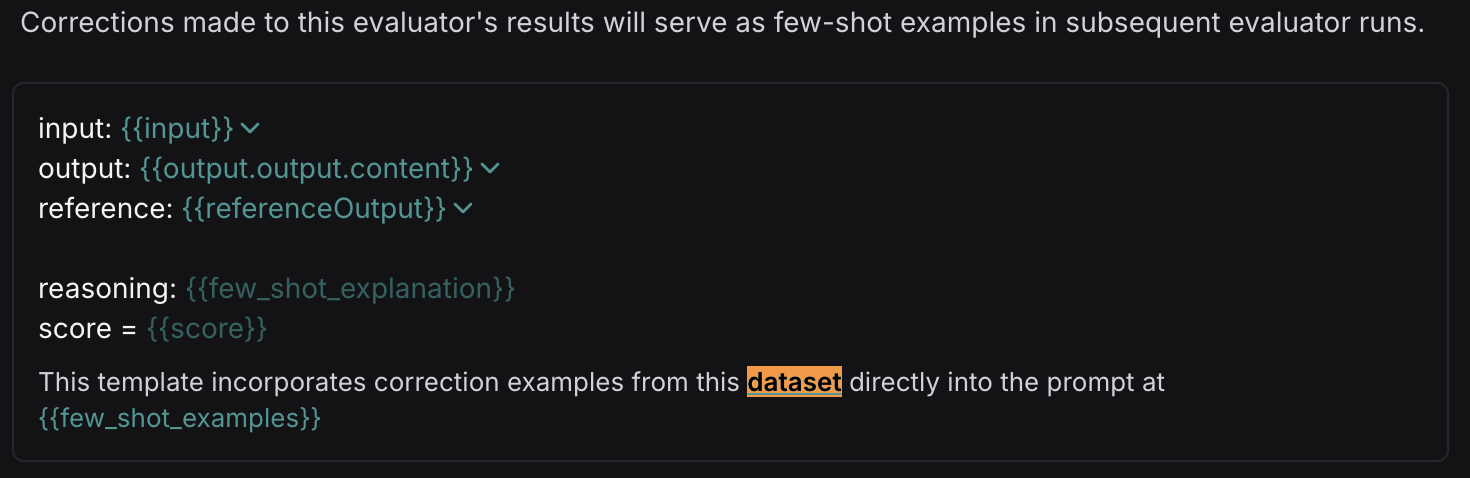
如何通过少样本示例改进评估器
当您无法通过编程方式评估系统时,使用 LLM-as-a-judge 评估器会非常有帮助。然而,它们的有效性取决于其质量以及与人工评审反馈的一致性。LangSmith 提供了通过人工修正来提高 LLM-as-a-judge 评估器与人类偏好一致性的能力。
人工修正会使用少样本示例自动插入到您的评估器提示词中。少样本示例是一种受少样本提示启发的技巧,它通过少量高质量示例来指导模型的输出。
本指南介绍了如何将少样本示例设置为 LLM-as-a-judge 评估器的一部分,以及如何将修正应用于反馈分数。
少样本示例的工作原理
- 少样本示例通过
{{Few-shot examples}}变量添加到您的评估器提示词中 - 创建带有少样本示例的评估器将自动为您创建一个数据集,一旦您开始进行修正,该数据集将自动填充少样本示例
- 在运行时,这些示例将插入到评估器中,作为其输出的指导——这将有助于评估器更好地与人类偏好保持一致
配置评估器
目前,使用提示中心 (prompt hub) 的 LLM-as-a-judge 评估器不支持少样本示例,仅与使用 mustache 格式的提示词兼容。
在启用少样本示例之前,请设置您的 LLM-as-a-judge 评估器。如果您尚未完成此操作,请遵循LLM-as-a-judge 评估器指南中的步骤。
1. 配置变量映射
每个少样本示例都根据配置中指定的变量映射进行格式化。少样本示例的变量映射应包含与您的主提示词相同的变量,以及一个 few_shot_explanation 变量和一个 score 变量,其中 score 变量应与您的反馈键 (feedback key) 具有相同的名称。
例如,如果您的主提示词包含变量 question 和 response,并且您的评估器输出 correctness 分数,那么您的少样本提示词应包含变量 question、response、few_shot_explanation 和 correctness。
2. 指定使用的少样本示例数量
您还可以指定要使用的少样本示例数量。默认值为 5。如果您的示例非常长,您可能希望将此数字设置得更低以节省 token;而如果您的示例往往很短,您可以设置更高的数字,以便为评估器提供更多示例进行学习。如果您的数据集中示例数量多于此数字,我们将为您随机选择。
进行修正
当您开始记录跟踪或运行实验时,您可能会不同意评估器给出的一些分数。当您对这些分数进行修正时,您将开始看到示例填充到您的修正数据集中。在进行修正时,请务必附上解释——这些解释将替代 few_shot_explanation 变量填充到您的评估器提示词中。
少样本示例的输入将是来自您的链/数据集的输入、输出和参考(如果这是离线评估器)中的相关字段。输出将是修正后的评估器分数和您在进行修正时创建的解释。您可以根据需要自由编辑这些内容。以下是修正数据集中少样本示例的一个例子
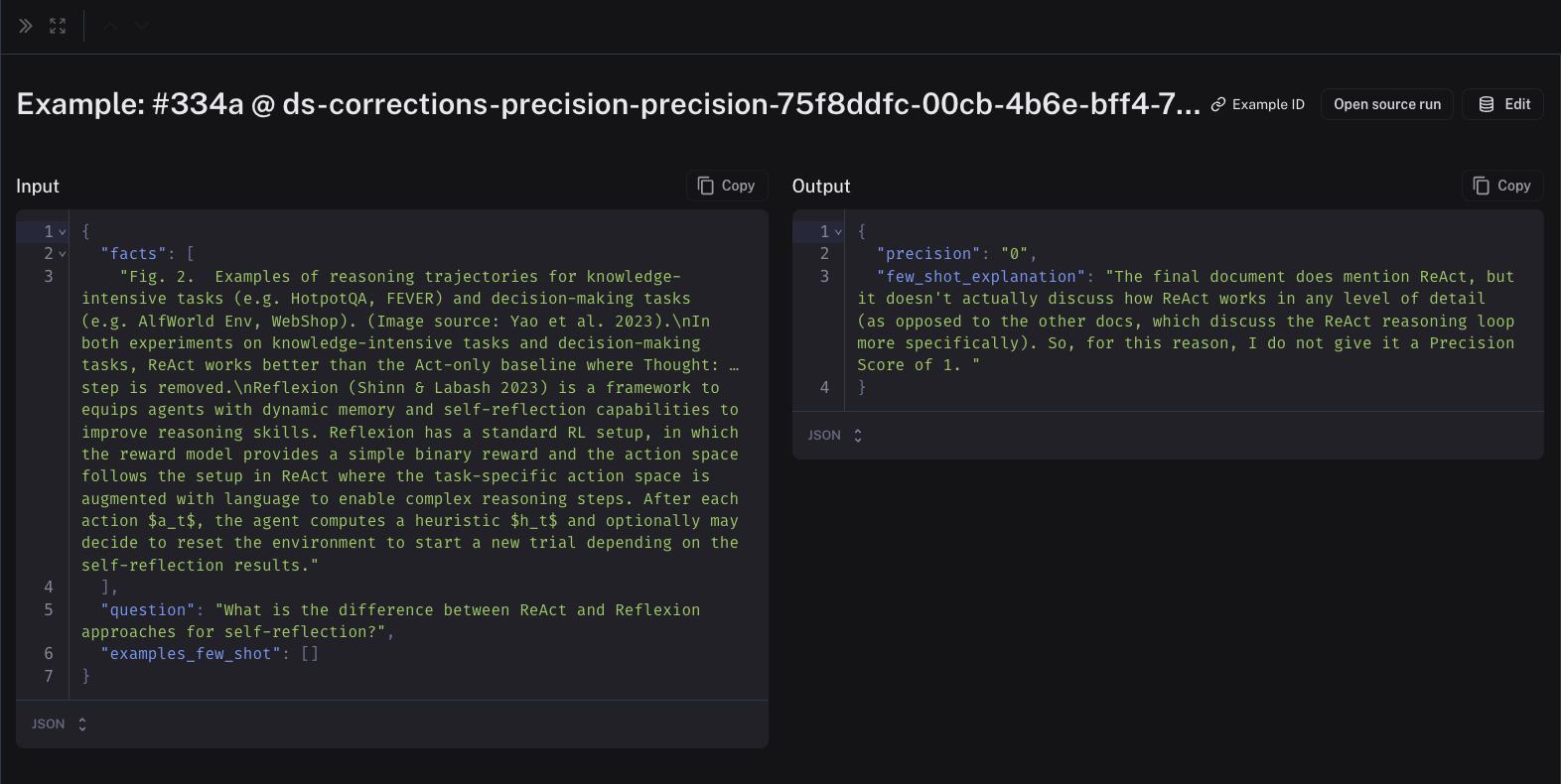
请注意,修正可能需要一到两分钟才能填充到您的少样本数据集中。一旦它们在那里,您的评估器未来的运行将把它们包含在提示词中!
查看您的修正数据集
为了查看您的修正数据集
- 在线评估器:选择您的运行规则并点击编辑规则
- 离线评估器:选择您的评估器并点击编辑评估器
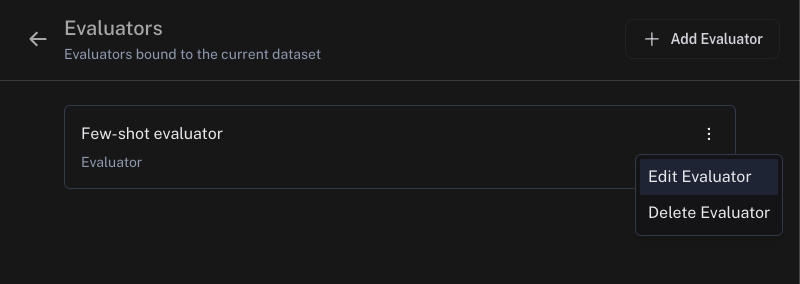
前往使用少样本示例提高评估器准确性部分中链接的您的修正数据集。您可以在数据集中查看和更新您的少样本示例。