如何运行成对评估
LangSmith 支持以比较方式评估**现有**实验。这允许您对多个实验的输出进行相互评分,而不是局限于一次评估一个输出。想象一下LMSYS 聊天机器人竞技场——概念是相同的!为此,请使用 evaluate() 函数并提供两个现有实验。
如果您尚未创建要比较的实验,请查看我们的快速入门或操作指南以开始进行评估。
evaluate() 比较参数
本指南要求 langsmith Python 版本 >=0.2.0 或 JS 版本 >=0.2.9。
最简单地,evaluate / aevaluate 函数接受以下参数
| 参数 | 描述 |
|---|---|
目标 | 您希望相互评估的两个**现有实验**的列表。它们可以是 UUID 或实验名称。 |
评估器 | 您希望附加到此评估的成对评估器列表。请参阅下文了解如何定义它们。 |
除此之外,您还可以传入以下可选参数
| 参数 | 描述 |
|---|---|
randomize_order / randomizeOrder | 一个可选的布尔值,指示是否应为每次评估随机化输出的顺序。这是最小化提示中位置偏差的策略:通常,LLM 会根据顺序偏向其中一个响应。这主要应通过提示工程来解决,但这是另一种可选的缓解措施。默认为 False。 |
experiment_prefix / experimentPrefix | 一个前缀,将附加到成对实验名称的开头。默认为 None。 |
描述 | 成对实验的描述。默认为 None。 |
max_concurrency / maxConcurrency | 要运行的最大并发评估数。默认为 5。 |
客户端 | 要使用的 LangSmith 客户端。默认为 None。 |
元数据 | 要附加到成对实验的元数据。默认为 None。 |
load_nested / loadNested | 是否加载实验的所有子运行。当为 False 时,只有根轨迹会传递给您的评估器。默认为 False。 |
定义成对评估器
成对评估器只是具有预期签名的函数。
评估器参数
自定义评估器函数必须具有特定的参数名称。它们可以接受以下参数的任何子集
inputs: dict:一个字典,包含数据集中单个示例对应的输入。outputs: list[dict]:一个包含两个元素的字典列表,表示每个实验针对给定输入产生的输出。reference_outputs/referenceOutputs: dict:一个字典,包含与示例关联的参考输出(如果可用)。runs: list[Run]:一个包含两个元素的列表,表示两个实验针对给定示例生成的完整 运行 (Run) 对象。如果您需要访问中间步骤或每个运行的元数据,请使用此项。example: Example:完整的 示例 (Example) 数据集,包括示例输入、输出(如果可用)和元数据(如果可用)。
对于大多数用例,您只需要 inputs、outputs 和 reference_outputs / referenceOutputs。run 和 example 仅在您需要应用程序实际输入和输出之外的额外轨迹或示例元数据时才有用。
评估器输出
自定义评估器应返回以下类型之一
Python 和 JS/TS
dict:包含以下键的字典key:表示将被记录的反馈键scores:一个将运行 ID 映射到该运行分数的映射。comment:一个字符串。最常用于模型推理。
目前仅限 Python
list[int | float | bool]:一个包含两个分数项的列表。该列表的顺序与runs/outputs评估器参数的顺序相同。评估器函数名称用作反馈键。
请注意,您应该选择一个与运行上的标准反馈不同的反馈键。我们建议使用 pairwise_ 或 ranked_ 作为成对反馈键的前缀。
运行成对评估
以下示例使用一个提示,该提示要求 LLM 判断两个 AI 助手响应中哪个更好。它使用结构化输出解析 AI 的响应:0、1 或 2。
在下面的 Python 示例中,我们从LangChain Hub中拉取了此结构化提示,并将其与 LangChain 聊天模型包装器一起使用。
LangChain 的使用是完全可选的。为了说明这一点,TypeScript 示例直接使用了 OpenAI SDK。
- Python
- TypeScript
要求 langsmith>=0.2.0
from langchain import hub
from langchain.chat_models import init_chat_model
from langsmith import evaluate
# See the prompt: https://smith.langchain.com/hub/langchain-ai/pairwise-evaluation-2
prompt = hub.pull("langchain-ai/pairwise-evaluation-2")
model = init_chat_model("gpt-4o")
chain = prompt | model
def ranked_preference(inputs: dict, outputs: list[dict]) -> list:
# Assumes example inputs have a 'question' key and experiment
# outputs have an 'answer' key.
response = chain.invoke({
"question": inputs["question"],
"answer_a": outputs[0].get("answer", "N/A"),
"answer_b": outputs[1].get("answer", "N/A"),
})
if response["Preference"] == 1:
scores = [1, 0]
elif response["Preference"] == 2:
scores = [0, 1]
else:
scores = [0, 0]
return scores
evaluate(
("experiment-1", "experiment-2"), # Replace with the names/IDs of your experiments
evaluators=[ranked_preference],
randomize_order=True,
max_concurrency=4,
)
要求 langsmith>=0.2.9
import { evaluate} from "langsmith/evaluation";
import { Run } from "langsmith/schemas";
import { wrapOpenAI } from "langsmith/wrappers";
import OpenAI from "openai";
import { z } from "zod";
const openai = wrapOpenAI(new OpenAI());
async function rankedPreference({
inputs,
runs,
}: {
inputs: Record<string, any>;
runs: Run[];
}) {
const scores: Record<string, number> = {};
const [runA, runB] = runs;
if (!runA || !runB) throw new Error("Expected at least two runs");
const payload = {
question: inputs.question,
answer_a: runA?.outputs?.output ?? "N/A",
answer_b: runB?.outputs?.output ?? "N/A",
};
const output = await openai.chat.completions.create({
model: "gpt-4-turbo",
messages: [
{
role: "system",
content: [
"Please act as an impartial judge and evaluate the quality of the responses provided by two AI assistants to the user question displayed below.",
"You should choose the assistant that follows the user's instructions and answers the user's question better.",
"Your evaluation should consider factors such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of their responses.",
"Begin your evaluation by comparing the two responses and provide a short explanation.",
"Avoid any position biases and ensure that the order in which the responses were presented does not influence your decision.",
"Do not allow the length of the responses to influence your evaluation. Do not favor certain names of the assistants. Be as objective as possible.",
].join(" "),
},
{
role: "user",
content: [
`[User Question] ${payload.question}`,
`[The Start of Assistant A's Answer] ${payload.answer_a} [The End of Assistant A's Answer]`,
`The Start of Assistant B's Answer] ${payload.answer_b} [The End of Assistant B's Answer]`,
].join("\n\n"),
},
],
tool_choice: {
type: "function",
function: { name: "Score" },
},
tools: [
{
type: "function",
function: {
name: "Score",
description: [
`After providing your explanation, output your final verdict by strictly following this format:`,
`Output "1" if Assistant A answer is better based upon the factors above.`,
`Output "2" if Assistant B answer is better based upon the factors above.`,
`Output "0" if it is a tie.`,
].join(" "),
parameters: {
type: "object",
properties: {
Preference: {
type: "integer",
description: "Which assistant answer is preferred?",
},
},
},
},
},
],
});
const { Preference } = z
.object({ Preference: z.number() })
.parse(
JSON.parse(output.choices[0].message.tool_calls[0].function.arguments)
);
if (Preference === 1) {
scores[runA.id] = 1;
scores[runB.id] = 0;
} else if (Preference === 2) {
scores[runA.id] = 0;
scores[runB.id] = 1;
} else {
scores[runA.id] = 0;
scores[runB.id] = 0;
}
return { key: "ranked_preference", scores };
}
await evaluate(["earnest-name-40", "reflecting-pump-91"], {
evaluators: [rankedPreference],
});
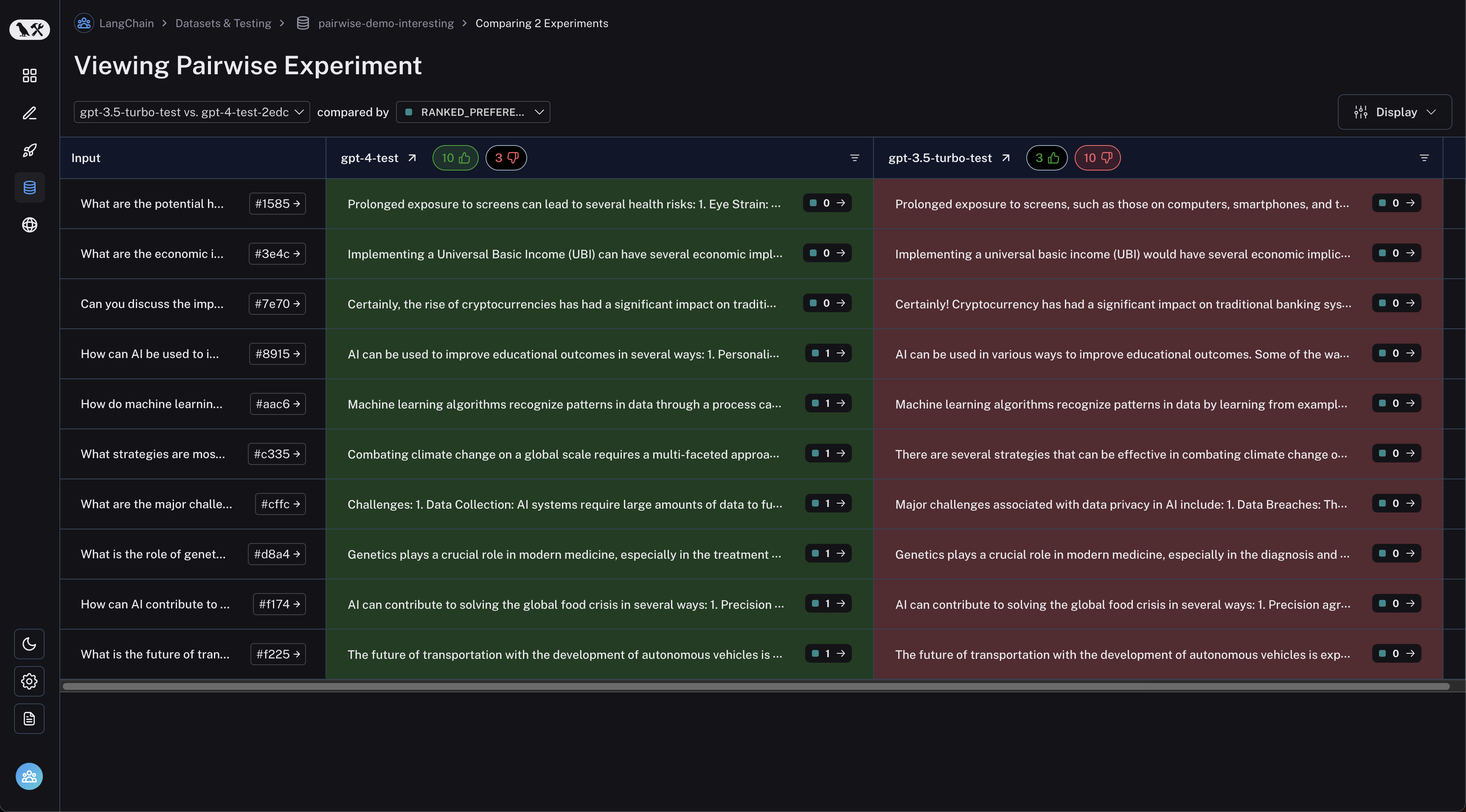
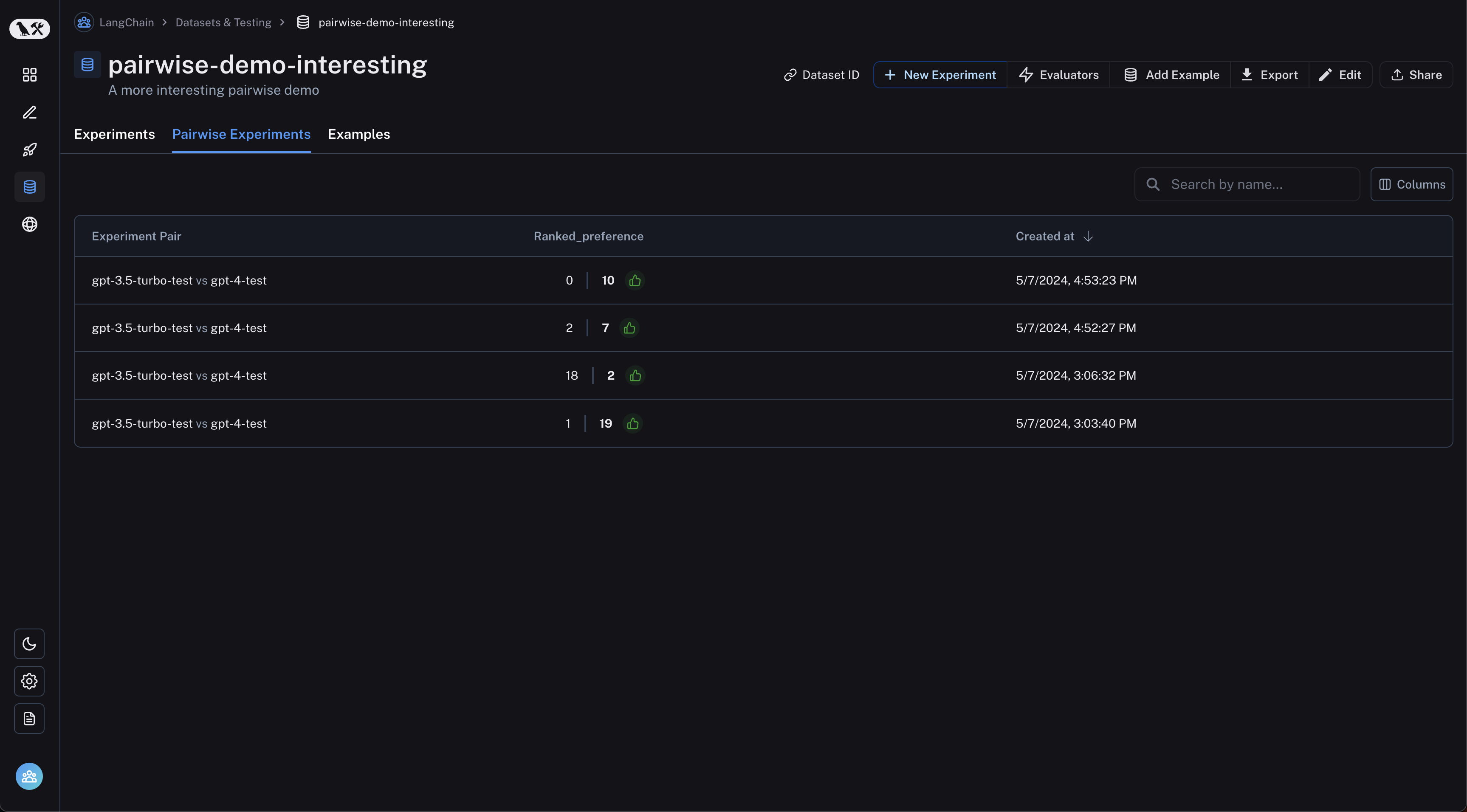
查看成对实验
从数据集页面导航到“成对实验”选项卡
单击您想要检查的成对实验,您将进入比较视图

您可以通过单击表格标题中的点赞/点踩按钮来过滤出第一个实验表现更好或反之的运行