使用 LangSmith 运行 SWE-bench
SWE-bench 是开发者用来测试其编码代理的最流行(也最困难!)的基准测试之一。在本教程中,我们将向您展示如何将 SWE-bench 数据集加载到 LangSmith 中并轻松对其进行评估,这让您比使用现成的 SWE-bench 评估套件更好地了解代理的行为。这使您能够更快地定位特定问题,并迅速迭代您的代理以提高性能!
加载数据
为了加载数据,我们将从 Hugging Face 拉取 dev 分割数据,但根据您的用例,您可能希望拉取 test 或 train 分割数据,如果您想合并多个分割数据,可以使用 pd.concat。
import pandas as pd
splits = {'dev': 'data/dev-00000-of-00001.parquet', 'test': 'data/test-00000-of-00001.parquet', 'train': 'data/train-00000-of-00001.parquet'}
df = pd.read_parquet("hf://datasets/princeton-nlp/SWE-bench/" + splits["dev"])
编辑 'version' 列
这是非常重要的一步!如果跳过,其余代码将无法运行!
version 列包含所有字符串值,但它们都以浮点数格式存在,因此当您上传 CSV 以创建 LangSmith 数据集时,它们会被转换为浮点数。尽管您可以在实验期间将值转换为字符串,但问题出现在像 "0.10" 这样的值上。当转换为浮点数时,您会得到值 0.1,如果将其转换为字符串,则会变成 "0.1"——这会在执行您提议的补丁时导致键错误。
为了解决这个问题,我们需要让 LangSmith 停止尝试将 version 列转换为浮点数。为此,我们可以为每个值添加一个不兼容浮点数的字符串前缀。然后,在评估时,我们需要根据此前缀进行分割以获取实际的 version 值。这里我们选择的前缀是字符串 "version:"。
未来将增加在 LangSmith 上传 CSV 时选择列类型的功能,以避免使用此变通方法。
df['version'] = df['version'].apply(lambda x: f"version:{x}")
将数据上传到 LangSmith
保存为 CSV
要将数据上传到 LangSmith,我们首先需要将其保存为 CSV 文件,这可以通过 pandas 提供的 to_csv 函数完成。请确保将此文件保存到您易于访问的位置。
df.to_csv("./../SWE-bench.csv",index=False)
手动上传 CSV 到 LangSmith
现在我们准备好将 CSV 上传到 LangSmith。进入 LangSmith 网站 (smith.langchain.com) 后,导航到左侧导航栏的 Datasets & Testing 标签页,然后点击右上角的 + New Dataset 按钮。
然后点击顶部的 Upload CSV 按钮,选择您上一步保存的 CSV 文件。之后您可以为您的数据集命名和添加描述。
接下来,选择 Key-Value 作为数据集类型。最后,进入 Create Schema 部分,将所有键添加为 Input fields。本例中没有 Output fields,因为我们的评估器不与参考值进行比较,而是将在 Docker 容器中运行我们实验的输出,以确保代码实际解决了 PR 问题。
填充完 Input fields(并保持 Output fields 为空!)后,您可以点击右上角的蓝色 Create 按钮,您的数据集就创建成功了!
以编程方式上传 CSV 到 LangSmith
或者,您可以使用 SDK 将 CSV 上传到 LangSmith,如下面的代码块所示
dataset = client.upload_csv(
csv_file="./../SWE-bench-dev.csv",
input_keys=list(df.columns),
output_keys=[],
name="swe-bench-programatic-upload",
description="SWE-bench dataset",
data_type="kv"
)
创建数据集分割以进行更快测试
由于 SWE-bench 评估器在所有示例上运行时需要很长时间,您可以创建一个“测试”分割,以便快速测试评估器和您的代码。阅读此指南以了解更多关于管理数据集分割的信息,或者观看这个简短视频,它展示了如何操作(要进入视频的起始页面,只需点击您上面创建的数据集并前往 Examples 标签页)
运行我们的预测函数
在 SWE-bench 上运行评估与您通常在 LangSmith 上运行的大多数评估略有不同,因为我们没有参考输出。因此,我们首先生成所有输出而不运行评估器(请注意 evaluate 调用没有设置 evaluators 参数)。在这种情况下,我们返回了一个虚拟的预测函数,但您可以将您的代理逻辑插入到 predict 函数中,使其按预期工作。
from langsmith import evaluate
from langsmith import Client
client = Client()
def predict(inputs: dict):
return {"instance_id":inputs['instance_id'],"model_patch":"None","model_name_or_path":"test-model"}
result = evaluate(
predict,
data=client.list_examples(dataset_id="a9bffcdf-1dfe-4aef-8805-8806f0110067",splits=["test"]),
)
在以下链接查看实验 'perfect-lip-22' 的评估结果:https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/a9bffcdf-1dfe-4aef-8805-8806f0110067/compare?selectedSessions=182de5dc-fc9d-4065-a3e1-34527f952fd8
3it [00:00, 24.48it/s]
使用 SWE-bench 评估我们的预测
现在我们可以运行以下代码,在 Docker 中运行我们上面生成的预测补丁。此代码是根据 SWE-bench 的 run_evaluation.py 文件稍作修改的。
基本上,该代码设置了 Docker 镜像以并行运行预测,这大大减少了评估所需的时间。此屏幕截图解释了 SWE-bench 在底层如何进行评估的基础知识。要全面理解,请务必阅读 GitHub 仓库中的代码。
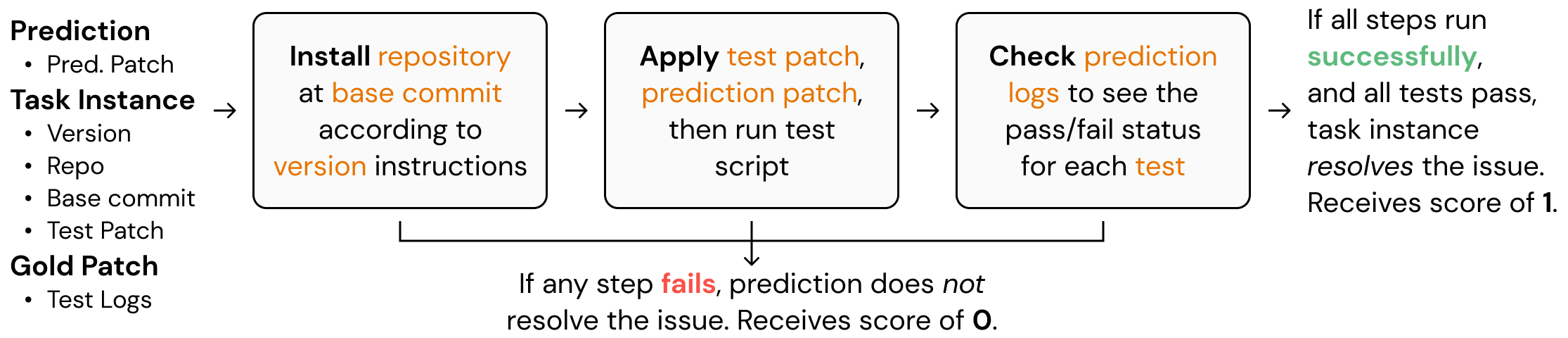
函数 convert_runs_to_langsmith_feedback 将 Docker 文件生成的日志转换为一个美观的 .json 文件,该文件以 LangSmith 典型的键/分数方式包含反馈。
from swebench.harness.run_evaluation import run_instances
import resource
import docker
from swebench.harness.docker_utils import list_images, clean_images
from swebench.harness.docker_build import build_env_images
from pathlib import Path
import json
import os
RUN_EVALUATION_LOG_DIR = Path("logs/run_evaluation")
LANGSMITH_EVALUATION_DIR = './langsmith_feedback/feedback.json'
def convert_runs_to_langsmith_feedback(
predictions: dict,
full_dataset: list,
run_id: str
) -> float:
"""
Convert logs from docker containers into LangSmith feedback.
Args:
predictions (dict): Predictions dict generated by the model
full_dataset (list): List of all instances
run_id (str): Run ID
"""
feedback_for_all_instances = {}
for instance in full_dataset:
feedback_for_instance = []
instance_id = instance['instance_id']
prediction = predictions[instance_id]
if prediction.get("model_patch", None) in ["", None]:
# Prediction returned an empty patch
feedback_for_all_instances[prediction['run_id']] = [{"key":"non-empty-patch","score":0},
{"key":"completed-patch","score":0},
{"key":"resolved-patch","score":0}]
continue
feedback_for_instance.append({"key":"non-empty-patch","score":1})
report_file = (
RUN_EVALUATION_LOG_DIR
/ run_id
/ prediction["model_name_or_path"].replace("/", "__")
/ prediction['instance_id']
/ "report.json"
)
if report_file.exists():
# If report file exists, then the instance has been run
feedback_for_instance.append({"key":"completed-patch","score":1})
report = json.loads(report_file.read_text())
# Check if instance actually resolved the PR
if report[instance_id]["resolved"]:
feedback_for_instance.append({"key":"resolved-patch","score":1})
else:
feedback_for_instance.append({"key":"resolved-patch","score":0})
else:
# The instance did not run successfully
feedback_for_instance += [{"key":"completed-patch","score":0},{"key":"resolved-patch","score":0}]
feedback_for_all_instances[prediction['run_id']] = feedback_for_instance
os.makedirs(os.path.dirname(LANGSMITH_EVALUATION_DIR), exist_ok=True)
with open(LANGSMITH_EVALUATION_DIR, 'w') as json_file:
json.dump(feedback_for_all_instances, json_file)
def evaluate_predictions(
dataset: list,
predictions: list,
max_workers: int,
force_rebuild: bool,
cache_level: str,
clean: bool,
open_file_limit: int,
run_id: str,
timeout: int,
):
"""
Run evaluation harness for the given dataset and predictions.
"""
# set open file limit
assert len(run_id) > 0, "Run ID must be provided"
resource.setrlimit(resource.RLIMIT_NOFILE, (open_file_limit, open_file_limit))
client = docker.from_env()
existing_images = list_images(client)
print(f"Running {len(dataset)} unevaluated instances...")
# build environment images + run instances
build_env_images(client, dataset, force_rebuild, max_workers)
run_instances(predictions, dataset, cache_level, clean, force_rebuild, max_workers, run_id, timeout)
# clean images + make final report
clean_images(client, existing_images, cache_level, clean)
convert_runs_to_langsmith_feedback(predictions,dataset,run_id)
dataset = []
predictions = {}
for res in result:
predictions[res['run'].outputs['instance_id']] = {**res['run'].outputs,**{"run_id":str(res['run'].id)}}
dataset.append(res['run'].inputs['inputs'])
for d in dataset:
d['version'] = d['version'].split(":")[1]
evaluate_predictions(dataset,predictions,max_workers=8,force_rebuild=False,cache_level="env",clean=False \
,open_file_limit=4096,run_id="test",timeout=1_800)
Running 3 unevaluated instances...
Base image sweb.base.arm64:latest already exists, skipping build.
Base images built successfully.
Total environment images to build: 2
Building environment images: 100%|██████████| 2/2 [00:47<00:00, 23.94s/it]
All environment images built successfully.
Running 3 instances...
0%| | 0/3 [00:00<?, ?it/s]
Evaluation error for sqlfluff__sqlfluff-884: >>>>> Patch Apply Failed:
patch unexpectedly ends in middle of line
patch: **** Only garbage was found in the patch input.
Check (logs/run_evaluation/test/test-model/sqlfluff__sqlfluff-884/run_instance.log) for more information.
Evaluation error for sqlfluff__sqlfluff-4151: >>>>> Patch Apply Failed:
patch unexpectedly ends in middle of line
patch: **** Only garbage was found in the patch input.
Check (logs/run_evaluation/test/test-model/sqlfluff__sqlfluff-4151/run_instance.log) for more information.
Evaluation error for sqlfluff__sqlfluff-2849: >>>>> Patch Apply Failed:
patch: **** Only garbage was found in the patch input.
patch unexpectedly ends in middle of line
Check (logs/run_evaluation/test/test-model/sqlfluff__sqlfluff-2849/run_instance.log) for more information.
100%|██████████| 3/3 [00:30<00:00, 10.04s/it]
All instances run.
Cleaning cached images...
Removed 0 images.
将评估结果发送到 LangSmith
现在,我们可以使用 evaluate_existing 函数将评估反馈发送到 LangSmith。在这种情况下,我们的评估函数非常简单,因为上面的 convert_runs_to_langsmith_feedback 函数通过将所有反馈保存到一个文件中,大大简化了我们的工作。
from langsmith import evaluate_existing
from langsmith.schemas import Example, Run
def swe_bench_evaluator(run: Run, example: Example):
with open(LANGSMITH_EVALUATION_DIR, 'r') as json_file:
langsmith_eval = json.load(json_file)
return {"results": langsmith_eval[str(run.id)]}
experiment_name = result.experiment_name
evaluate_existing(experiment_name, evaluators=[swe_bench_evaluator])
View the evaluation results for experiment: 'perfect-lip-22' at:
https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/a9bffcdf-1dfe-4aef-8805-8806f0110067/compare?selectedSessions=182de5dc-fc9d-4065-a3e1-34527f952fd8
3it [00:01, 1.52it/s]
<ExperimentResults perfect-lip-22>
运行后,我们可以转到数据集的实验选项卡,检查我们的反馈键是否已正确分配。如果已正确分配,您应该会看到类似下图的内容