评估复杂代理
在本教程中,我们将构建一个客户支持机器人,帮助用户浏览数字音乐商店。然后,我们将介绍对聊天机器人运行评估的三种最有效类型
我们将使用 LangGraph 构建我们的代理,但这里展示的技术和 LangSmith 功能是与框架无关的。
设置
配置环境
让我们安装所需的依赖项
pip install -U langgraph langchain[openai]
让我们为 OpenAI 和 LangSmith 设置环境变量
import getpass
import os
def _set_env(var: str) -> None:
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"Set {var}: ")
os.environ["LANGSMITH_TRACING"] = "true"
_set_env("LANGSMITH_API_KEY")
_set_env("OPENAI_API_KEY")
下载数据库
我们将为本教程创建一个 SQLite 数据库。SQLite 是一个轻量级数据库,易于设置和使用。我们将加载 chinook 数据库,这是一个代表数字媒体商店的示例数据库。在此处查找有关数据库的更多信息这里。
为方便起见,我们已将数据库托管在公共 GCS 存储桶中
import requests
url = "https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db"
response = requests.get(url)
if response.status_code == 200:
# Open a local file in binary write mode
with open("chinook.db", "wb") as file:
# Write the content of the response (the file) to the local file
file.write(response.content)
print("File downloaded and saved as Chinook.db")
else:
print(f"Failed to download the file. Status code: {response.status_code}")
这是数据库中的数据示例
import sqlite3 ...
[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]
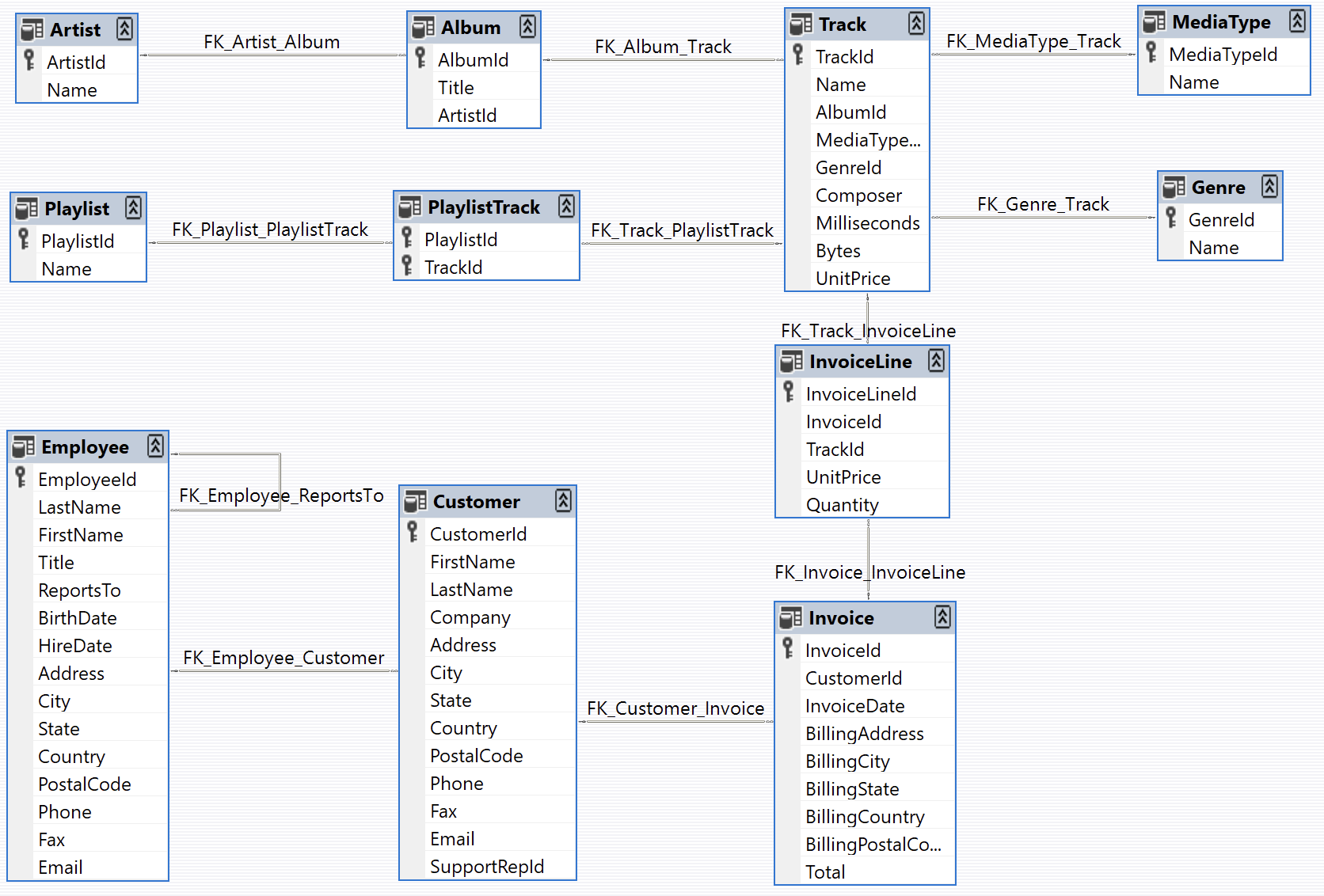
这是数据库架构(图片来自 https://github.com/lerocha/chinook-database)
定义客户支持代理
我们将创建一个对数据库访问受限的 LangGraph 代理。出于演示目的,我们的代理将支持两种基本类型的请求
- 查询:客户可以根据其他识别信息查询歌曲名称、艺术家姓名和专辑。例如:“你们有什么 Jimi Hendrix 的歌曲?”
- 退款:客户可以请求对其过去的购买进行退款。例如:“我叫 Claude Shannon,我想退还我上周购买的一件商品,您能帮我吗?”
为了简化此演示,我们将通过删除相应的数据库记录来实现退款。我们将跳过实现用户身份验证和其他生产安全措施。
代理的逻辑将结构化为两个独立的子图(一个用于查询,一个用于退款),并有一个父图将请求路由到适当的子图。
退款代理
让我们构建退款处理代理。此代理需要
- 在数据库中查找客户的购买记录
- 删除相关的发票(Invoice)和发票明细(InvoiceLine)记录以处理退款
我们将创建两个 SQL 辅助函数
- 一个通过删除记录执行退款的函数
- 一个查询客户购买历史的函数
为了便于测试,我们将为这些函数添加“模拟”模式。启用模拟模式时,函数将模拟数据库操作,而不会实际修改任何数据。
import sqlite3
def _refund(invoice_id: int | None, invoice_line_ids: list[int] | None, mock: bool = False) -> float: ...
def _lookup( ...
现在让我们定义图。我们将使用一个简单的架构,包含三个主要路径
- 从对话中提取客户和购买信息
- 将请求路由到三个路径之一
- 退款路径:如果我们有足够的购买详情(发票 ID 或发票明细 ID)来处理退款
- 查询路径:如果我们有足够的客户信息(姓名和电话)来搜索他们的购买历史
- 响应路径:如果我们需要更多信息,则响应用户,请求所需的具体详情
图的状态将跟踪
- 对话历史(用户和代理之间的消息)
- 从对话中提取的所有客户和购买信息
- 要发送给用户的下一条消息(后续文本)
from typing import Literal
import json
from langchain.chat_models import init_chat_model
from langchain_core.runnables import RunnableConfig
from langgraph.graph import END, StateGraph
from langgraph.graph.message import AnyMessage, add_messages
from langgraph.types import Command, interrupt
from tabulate import tabulate
from typing_extensions import Annotated, TypedDict
# Graph state.
class State(TypedDict):
"""Agent state."""
messages: Annotated[list[AnyMessage], add_messages]
followup: str | None
invoice_id: int | None
invoice_line_ids: list[int] | None
customer_first_name: str | None
customer_last_name: str | None
customer_phone: str | None
track_name: str | None
album_title: str | None
artist_name: str | None
purchase_date_iso_8601: str | None
# Instructions for extracting the user/purchase info from the conversation.
gather_info_instructions = """You are managing an online music store that sells song tracks. \
Customers can buy multiple tracks at a time and these purchases are recorded in a database as \
an Invoice per purchase and an associated set of Invoice Lines for each purchased track.
Your task is to help customers who would like a refund for one or more of the tracks they've \
purchased. In order for you to be able refund them, the customer must specify the Invoice ID \
to get a refund on all the tracks they bought in a single transaction, or one or more Invoice \
Line IDs if they would like refunds on individual tracks.
Often a user will not know the specific Invoice ID(s) or Invoice Line ID(s) for which they \
would like a refund. In this case you can help them look up their invoices by asking them to \
specify:
- Required: Their first name, last name, and phone number.
- Optionally: The track name, artist name, album name, or purchase date.
If the customer has not specified the required information (either Invoice/Invoice Line IDs \
or first name, last name, phone) then please ask them to specify it."""
# Extraction schema, mirrors the graph state.
class PurchaseInformation(TypedDict):
"""All of the known information about the invoice / invoice lines the customer would like refunded. Do not make up values, leave fields as null if you don't know their value."""
invoice_id: int | None
invoice_line_ids: list[int] | None
customer_first_name: str | None
customer_last_name: str | None
customer_phone: str | None
track_name: str | None
album_title: str | None
artist_name: str | None
purchase_date_iso_8601: str | None
followup: Annotated[
str | None,
...,
"If the user hasn't enough identifying information, please tell them what the required information is and ask them to specify it.",
]
# Model for performing extraction.
info_llm = init_chat_model("gpt-4o-mini").with_structured_output(
PurchaseInformation, method="json_schema", include_raw=True
)
# Graph node for extracting user info and routing to lookup/refund/END.
async def gather_info(state: State) -> Command[Literal["lookup", "refund", END]]:
info = await info_llm.ainvoke(
[
{"role": "system", "content": gather_info_instructions},
*state["messages"],
]
)
parsed = info["parsed"]
if any(parsed[k] for k in ("invoice_id", "invoice_line_ids")):
goto = "refund"
elif all(
parsed[k]
for k in ("customer_first_name", "customer_last_name", "customer_phone")
):
goto = "lookup"
else:
goto = END
update = {"messages": [info["raw"]], **parsed}
return Command(update=update, goto=goto)
# Graph node for executing the refund.
# Note that here we inspect the runtime config for an "env" variable.
# If "env" is set to "test", then we don't actually delete any rows from our database.
# This will become important when we're running our evaluations.
def refund(state: State, config: RunnableConfig) -> dict:
# Whether to mock the deletion. True if the configurable var 'env' is set to 'test'.
mock = config.get("configurable", {}).get("env", "prod") == "test"
refunded = _refund(
invoice_id=state["invoice_id"], invoice_line_ids=state["invoice_line_ids"], mock=mock
)
response = f"You have been refunded a total of: ${refunded:.2f}. Is there anything else I can help with?"
return {
"messages": [{"role": "assistant", "content": response}],
"followup": response,
}
# Graph node for looking up the users purchases
def lookup(state: State) -> dict:
args = (
state[k]
for k in (
"customer_first_name",
"customer_last_name",
"customer_phone",
"track_name",
"album_title",
"artist_name",
"purchase_date_iso_8601",
)
)
results = _lookup(*args)
if not results:
response = "We did not find any purchases associated with the information you've provided. Are you sure you've entered all of your information correctly?"
followup = response
else:
response = f"Which of the following purchases would you like to be refunded for?\n\n```json{json.dumps(results, indent=2)}\n```"
followup = f"Which of the following purchases would you like to be refunded for?\n\n{tabulate(results, headers='keys')}"
return {
"messages": [{"role": "assistant", "content": response}],
"followup": followup,
"invoice_line_ids": [res["invoice_line_id"] for res in results],
}
# Building our graph
graph_builder = StateGraph(State)
graph_builder.add_node(gather_info)
graph_builder.add_node(refund)
graph_builder.add_node(lookup)
graph_builder.set_entry_point("gather_info")
graph_builder.add_edge("lookup", END)
graph_builder.add_edge("refund", END)
refund_graph = graph_builder.compile()
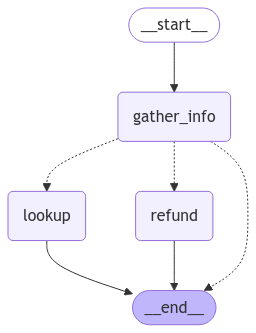
我们可以可视化我们的退款图
# Assumes you're in an interactive Python environment
from IPython.display import Image, display ...
查询代理
对于查询(即问答)代理,我们将使用简单的 ReACT 架构,并为代理提供工具,用于根据各种过滤器查找曲目名称、艺术家名称和专辑名称。例如,您可以查找特定艺术家的专辑,发行了特定名称歌曲的艺术家等。
from langchain.embeddings import init_embeddings
from langchain_core.tools import tool
from langchain_core.vectorstores import InMemoryVectorStore
from langgraph.prebuilt import create_react_agent
# Our SQL queries will only work if we filter on the exact string values that are in the DB.
# To ensure this, we'll create vectorstore indexes for all of the artists, tracks and albums
# ahead of time and use those to disambiguate the user input. E.g. if a user searches for
# songs by "prince" and our DB records the artist as "Prince", ideally when we query our
# artist vectorstore for "prince" we'll get back the value "Prince", which we can then
# use in our SQL queries.
def index_fields() -> tuple[InMemoryVectorStore, InMemoryVectorStore, InMemoryVectorStore]: ...
track_store, artist_store, album_store = index_fields()
# Agent tools
@tool
def lookup_track( ...
@tool
def lookup_album( ...
@tool
def lookup_artist( ...
# Agent model
qa_llm = init_chat_model("claude-3-5-sonnet-latest")
# The prebuilt ReACT agent only expects State to have a 'messages' key, so the
# state we defined for the refund agent can also be passed to our lookup agent.
qa_graph = create_react_agent(qa_llm, [lookup_track, lookup_artist, lookup_album])
display(Image(qa_graph.get_graph(xray=True).draw_mermaid_png()))

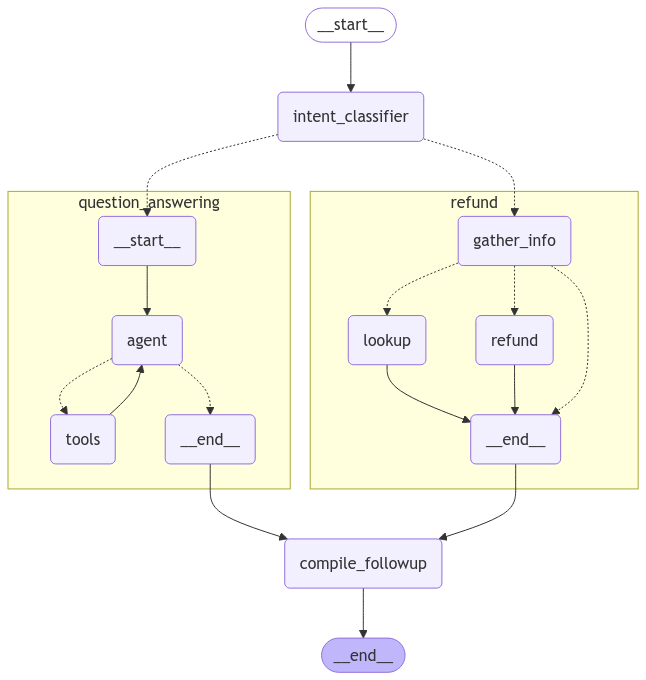
父代理
现在让我们定义一个父代理,它结合了我们的两个特定任务代理。父代理的唯一工作是通过对用户当前意图进行分类来路由到其中一个子代理,并将输出编译成后续消息。
# Schema for routing user intent.
# We'll use structured outputs to enforce that the model returns only
# the desired output.
class UserIntent(TypedDict):
"""The user's current intent in the conversation"""
intent: Literal["refund", "question_answering"]
# Routing model with structured output
router_llm = init_chat_model("gpt-4o-mini").with_structured_output(
UserIntent, method="json_schema", strict=True
)
# Instructions for routing.
route_instructions = """You are managing an online music store that sells song tracks. \
You can help customers in two types of ways: (1) answering general questions about \
tracks sold at your store, (2) helping them get a refund on a purhcase they made at your store.
Based on the following conversation, determine if the user is currently seeking general \
information about song tracks or if they are trying to refund a specific purchase.
Return 'refund' if they are trying to get a refund and 'question_answering' if they are \
asking a general music question. Do NOT return anything else. Do NOT try to respond to \
the user.
"""
# Node for routing.
async def intent_classifier(
state: State,
) -> Command[Literal["refund_agent", "question_answering_agent"]]:
response = router_llm.invoke(
[{"role": "system", "content": route_instructions}, *state["messages"]]
)
return Command(goto=response["intent"] + "_agent")
# Node for making sure the 'followup' key is set before our agent run completes.
def compile_followup(state: State) -> dict:
"""Set the followup to be the last message if it hasn't explicitly been set."""
if not state.get("followup"):
return {"followup": state["messages"][-1].content}
return {}
# Agent definition
graph_builder = StateGraph(State)
graph_builder.add_node(intent_classifier)
# Since all of our subagents have compatible state,
# we can add them as nodes directly.
graph_builder.add_node("refund_agent", refund_graph)
graph_builder.add_node("question_answering_agent", qa_graph)
graph_builder.add_node(compile_followup)
graph_builder.set_entry_point("intent_classifier")
graph_builder.add_edge("refund_agent", "compile_followup")
graph_builder.add_edge("question_answering_agent", "compile_followup")
graph_builder.add_edge("compile_followup", END)
graph = graph_builder.compile()
我们可以可视化包含所有子图的编译后的父图
display(Image(graph.get_graph().draw_mermaid_png()))
试用
让我们试用一下我们的自定义支持代理!
state = await graph.ainvoke(
{"messages": [{"role": "user", "content": "what james brown songs do you have"}]}
)
print(state["followup"])
I found 20 James Brown songs in the database, all from the album "Sex Machine". Here they are: ...
state = await graph.ainvoke({"messages": [
{
"role": "user",
"content": "my name is Aaron Mitchell and my number is +1 (204) 452-6452. I bought some songs by Led Zeppelin that i'd like refunded",
}
]})
print(state["followup"])
Which of the following purchases would you like to be refunded for? ...
评估
现在我们有了可测试的代理版本,让我们运行一些评估。代理评估可以至少关注 3 个方面
让我们运行每种类型的评估
最终响应评估器
首先,让我们创建一个数据集来评估代理的端到端性能。为简单起见,我们将对最终响应和轨迹评估使用相同的数据集,因此我们将为每个示例问题添加真实响应和轨迹。我们将在下一节中介绍轨迹。
from langsmith import Client
client = Client()
# Create a dataset
examples = [
{
"inputs": {
"question": "How many songs do you have by James Brown",
},
"outputs": {
"response": "We have 20 songs by James Brown",
"trajectory": ["question_answering_agent", "lookup_track"]
}
},
{
"inputs": {
"question": "My name is Aaron Mitchell and I'd like a refund.",
},
"outputs": {
"response": "I need some more information to help you with the refund. Please specify your phone number, the invoice ID, or the line item IDs for the purchase you'd like refunded.",
"trajectory": ["refund_agent"],
}
},
{
"inputs": {
"question": "My name is Aaron Mitchell and I'd like a refund on my Led Zeppelin purchases. My number is +1 (204) 452-6452",
},
"outputs": {
"response": 'Which of the following purchases would you like to be refunded for?\n\n invoice_line_id track_name artist_name purchase_date quantity_purchased price_per_unit\n----------------- -------------------------------- ------------- ------------------- -------------------- ----------------\n 267 How Many More Times Led Zeppelin 2009-08-06 00:00:00 1 0.99\n 268 What Is And What Should Never Be Led Zeppelin 2009-08-06 00:00:00 1 0.99',
"trajectory": ["refund_agent", "lookup"],
},
},
{
"inputs": {
"question": "Who recorded Wish You Were Here again? What other albums of there's do you have?",
},
"outputs": {
"response": "Wish You Were Here is an album by Pink Floyd",
"trajectory": ["question_answering_agent", "lookup_album"],
},
},
{
"inputs": {
"question": "I want a full refund for invoice 237",
},
"outputs": {
"response": "You have been refunded $0.99.",
"trajectory": ["refund_agent", "refund"],
}
},
]
dataset_name = "Chinook Customer Service Bot: E2E"
if not client.has_dataset(dataset_name=dataset_name):
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
我们将创建一个自定义的 LLM-as-a-judge 评估器,它使用另一个模型将我们代理在每个示例上的输出与参考响应进行比较,并判断它们是否等效
# LLM-as-judge instructions
grader_instructions = """You are a teacher grading a quiz.
You will be given a QUESTION, the GROUND TRUTH (correct) RESPONSE, and the STUDENT RESPONSE.
Here is the grade criteria to follow:
(1) Grade the student responses based ONLY on their factual accuracy relative to the ground truth answer.
(2) Ensure that the student response does not contain any conflicting statements.
(3) It is OK if the student response contains more information than the ground truth response, as long as it is factually accurate relative to the ground truth response.
Correctness:
True means that the student's response meets all of the criteria.
False means that the student's response does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct."""
# LLM-as-judge output schema
class Grade(TypedDict):
"""Compare the expected and actual answers and grade the actual answer."""
reasoning: Annotated[str, ..., "Explain your reasoning for whether the actual response is correct or not."]
is_correct: Annotated[bool, ..., "True if the student response is mostly or exactly correct, otherwise False."]
# Judge LLM
grader_llm = init_chat_model("gpt-4o-mini", temperature=0).with_structured_output(Grade, method="json_schema", strict=True)
# Evaluator function
async def final_answer_correct(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
"""Evaluate if the final response is equivalent to reference response."""
# Note that we assume the outputs has a 'response' dictionary. We'll need to make sure
# that the target function we define includes this key.
user = f"""QUESTION: {inputs['question']}
GROUND TRUTH RESPONSE: {reference_outputs['response']}
STUDENT RESPONSE: {outputs['response']}"""
grade = await grader_llm.ainvoke([{"role": "system", "content": grader_instructions}, {"role": "user", "content": user}])
return grade["is_correct"]
现在我们可以运行评估了。我们的评估器假设目标函数返回一个 'response' 键,因此让我们定义一个这样的目标函数。
还要记住,在我们的退款图中,我们将退款节点设置为可配置,这样如果我们指定 config={"env": "test"},我们将模拟退款而不会实际更新数据库。在调用图时,我们将在目标 run_graph 方法中使用此可配置变量
# Target function
async def run_graph(inputs: dict) -> dict:
"""Run graph and track the trajectory it takes along with the final response."""
result = await graph.ainvoke({"messages": [
{ "role": "user", "content": inputs['question']},
]}, config={"env": "test"})
return {"response": result["followup"]}
# Evaluation job and results
experiment_results = await client.aevaluate(
run_graph,
data=dataset_name,
evaluators=[final_answer_correct],
experiment_prefix="sql-agent-gpt4o-e2e",
num_repetitions=1,
max_concurrency=4,
)
experiment_results.to_pandas()
您可以在此处查看这些结果:LangSmith 链接。
轨迹评估器
随着代理变得更加复杂,它们有更多的潜在故障点。与其使用简单的通过/失败评估,通常最好使用能够提供部分分数的评估,即使代理没有达到正确的最终答案,但它采取了一些正确的步骤。
这就是轨迹评估的用武之地。轨迹评估
- 将代理采取的实际步骤序列与预期序列进行比较
- 根据正确完成的预期步骤数量计算分数
对于此示例,我们的端到端数据集包含我们期望代理采取的有序步骤列表。让我们创建一个评估器,检查代理的实际轨迹与这些预期步骤的匹配度,并计算完成的百分比
def trajectory_subsequence(outputs: dict, reference_outputs: dict) -> float:
"""Check how many of the desired steps the agent took."""
if len(reference_outputs['trajectory']) > len(outputs['trajectory']):
return False
i = j = 0
while i < len(reference_outputs['trajectory']) and j < len(outputs['trajectory']):
if reference_outputs['trajectory'][i] == outputs['trajectory'][j]:
i += 1
j += 1
return i / len(reference_outputs['trajectory'])
现在我们可以运行评估了。我们的评估器假设目标函数返回一个 'trajectory' 键,因此让我们定义一个这样的目标函数。我们需要使用 LangGraph 的流式传输能力 来记录轨迹。
请注意,我们正在重用与最终响应评估相同的数据集,因此我们可以同时运行两个评估器,并定义一个同时返回“response”和“trajectory”的目标函数。在实践中,为每种评估类型拥有单独的数据集通常很有用,这就是为什么我们在这里单独展示它们的原因
async def run_graph(inputs: dict) -> dict:
"""Run graph and track the trajectory it takes along with the final response."""
trajectory = []
# Set subgraph=True to stream events from subgraphs of the main graph: https://github.langchain.ac.cn/langgraph/how-tos/streaming-subgraphs/
# Set stream_mode="debug" to stream all possible events: https://github.langchain.ac.cn/langgraph/concepts/streaming
async for namespace, chunk in graph.astream({"messages": [
{
"role": "user",
"content": inputs['question'],
}
]}, subgraphs=True, stream_mode="debug"):
# Event type for entering a node
if chunk['type'] == 'task':
# Record the node name
trajectory.append(chunk['payload']['name'])
# Given how we defined our dataset, we also need to track when specific tools are
# called by our question answering ReACT agent. These tool calls can be found
# when the ToolsNode (named "tools") is invoked by looking at the AIMessage.tool_calls
# of the latest input message.
if chunk['payload']['name'] == 'tools' and chunk['type'] == 'task':
for tc in chunk['payload']['input']['messages'][-1].tool_calls:
trajectory.append(tc['name'])
return {"trajectory": trajectory}
experiment_results = await client.aevaluate(
run_graph,
data=dataset_name,
evaluators=[trajectory_subsequence],
experiment_prefix="sql-agent-gpt4o-trajectory",
num_repetitions=1,
max_concurrency=4,
)
experiment_results.to_pandas()
您可以在此处查看这些结果:LangSmith 链接。
单步评估器
虽然端到端测试能提供关于代理性能的最强信号,但为了调试和迭代代理,直接评估那些困难的特定步骤会很有帮助。
在我们的例子中,代理的关键部分是它能正确地将用户意图路由到“退款”路径或“问答”路径。让我们创建一个数据集并运行一些评估,以直接对这个组件进行压力测试。
# Create dataset
examples = [
{
"inputs": {"messages": [{"role": "user", "content": "i bought some tracks recently and i dont like them"}]},
"outputs": {"route": "refund_agent"},
},
{
"inputs": {"messages": [{"role": "user", "content": "I was thinking of purchasing some Rolling Stones tunes, any recommendations?"}]},
"outputs": {"route": "question_answering_agent"},
},
{
"inputs": {"messages": [{"role": "user", "content": "i want a refund on purchase 237"}, {"role": "assistant", "content": "I've refunded you a total of $1.98. How else can I help you today?"}, {"role": "user", "content": "did prince release any albums in 2000?"}]},
"outputs": {"route": "question_answering_agent"},
},
{
"inputs": {"messages": [{"role": "user", "content": "i purchased a cover of Yesterday recently but can't remember who it was by, which versions of it do you have?"}]},
"outputs": {"route": "question_answering_agent"},
},
]
dataset_name = "Chinook Customer Service Bot: Intent Classifier"
if not client.has_dataset(dataset_name=dataset_name):
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
# Evaluator
def correct(outputs: dict, reference_outputs: dict) -> bool:
"""Check if the agent chose the correct route."""
return outputs["route"] == reference_outputs["route"]
# Target function for running the relevant step
async def run_intent_classifier(inputs: dict) -> dict:
# Note that we can access and run the intent_classifier node of our graph directly.
command = await graph.nodes['intent_classifier'].ainvoke(inputs)
return {"route": command.goto}
# Run evaluation
experiment_results = await client.aevaluate(
run_intent_classifier,
data=dataset_name,
evaluators=[correct],
experiment_prefix="sql-agent-gpt4o-intent-classifier",
max_concurrency=4,
)
您可以在此处查看这些结果:LangSmith 链接。
参考代码
以下是包含上述所有代码的整合脚本
import json ...