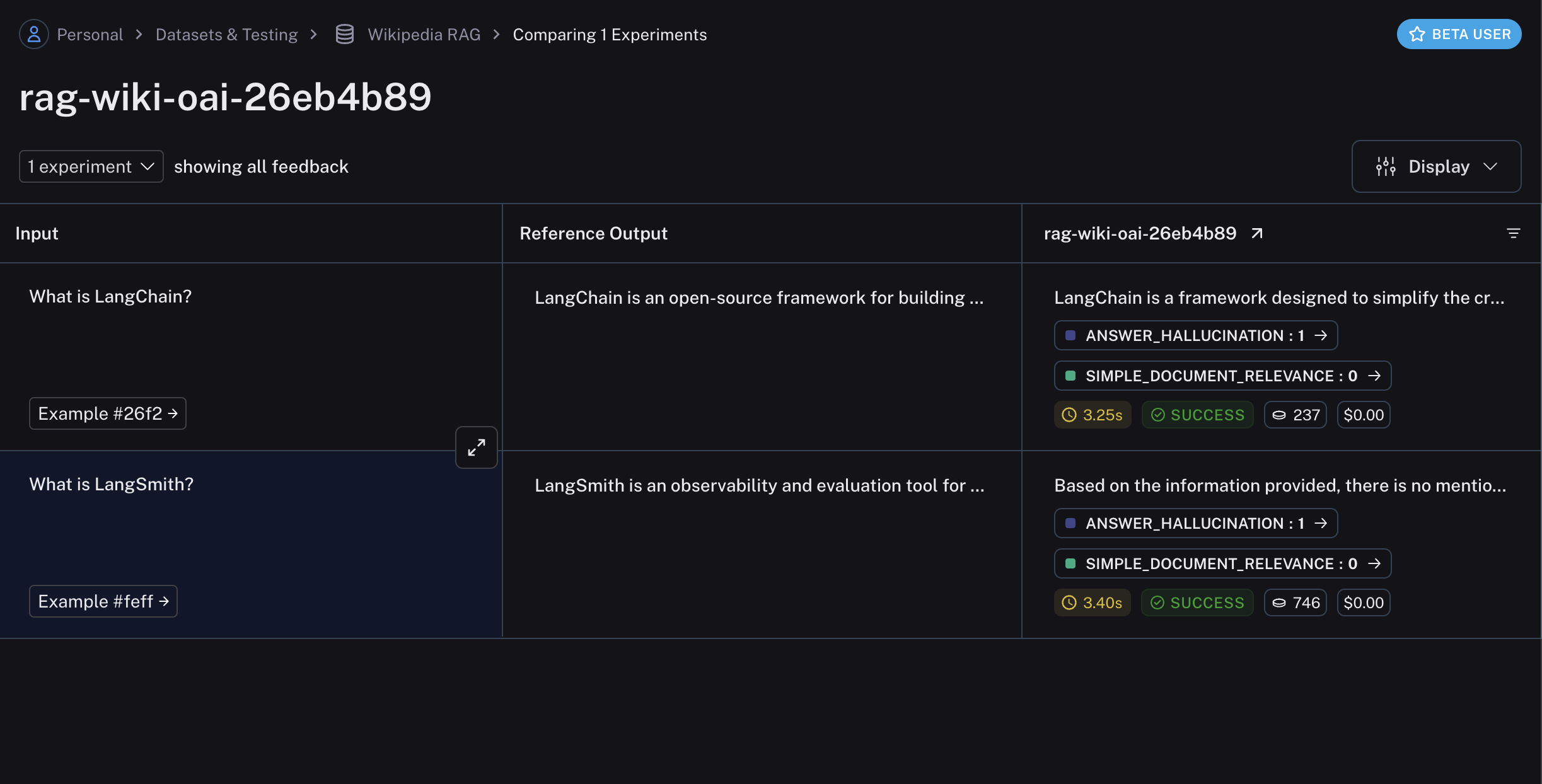
如何评估应用程序的中间步骤
虽然在许多场景中,评估任务的最终输出就足够了,但在某些情况下,您可能希望评估管道的中间步骤。
例如,对于检索增强生成 (RAG),您可能希望:
- 评估检索步骤,以确保根据输入查询检索到正确的文档。
- 评估生成步骤,以确保根据检索到的文档生成正确的答案。
在本指南中,我们将使用一个简单的、完全自定义的评估器来评估标准 1,并使用一个基于 LLM 的评估器来评估标准 2,以突出这两种情况。
为了评估管道的中间步骤,您的评估器函数应遍历并处理 `run`/`rootRun` 参数,它是一个包含管道中间步骤的 `Run` 对象。
1. 定义您的 LLM 管道
下面的 RAG 管道包括 1) 根据输入问题生成维基百科查询,2) 从维基百科检索相关文档,以及 3) 根据检索到的文档生成答案。
- Python
- TypeScript
pip install -U langsmith langchain[openai] wikipedia
yarn add langsmith langchain @langchain/openai wikipedia
- Python
- TypeScript
需要 langsmith>=0.3.13
import wikipedia as wp
from openai import OpenAI
from langsmith import traceable, wrappers
oai_client = wrappers.wrap_openai(OpenAI())
@traceable
def generate_wiki_search(question: str) -> str:
"""Generate the query to search in wikipedia."""
instructions = (
"Generate a search query to pass into wikipedia to answer the user's question. "
"Return only the search query and nothing more. "
"This will passed in directly to the wikipedia search engine."
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": question}
]
result = oai_client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
temperature=0,
)
return result.choices[0].message.content
@traceable(run_type="retriever")
def retrieve(query: str) -> list:
"""Get up to two search wikipedia results."""
results = []
for term in wp.search(query, results = 10):
try:
page = wp.page(term, auto_suggest=False)
results.append({
"page_content": page.summary,
"type": "Document",
"metadata": {"url": page.url}
})
except wp.DisambiguationError:
pass
if len(results) >= 2:
return results
@traceable
def generate_answer(question: str, context: str) -> str:
"""Answer the question based on the retrieved information."""
instructions = f"Answer the user's question based ONLY on the content below:\n\n{context}"
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": question}
]
result = oai_client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
temperature=0
)
return result.choices[0].message.content
@traceable
def qa_pipeline(question: str) -> str:
"""The full pipeline."""
query = generate_wiki_search(question)
context = "\n\n".join([doc["page_content"] for doc in retrieve(query)])
return generate_answer(question, context)
import OpenAI from "openai";
import wiki from "wikipedia";
import { Client } from "langsmith";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers";
const openai = wrapOpenAI(new OpenAI());
const generateWikiSearch = traceable(
async (input: { question: string }) => {
const messages = [
{
role: "system" as const,
content:
"Generate a search query to pass into Wikipedia to answer the user's question. Return only the search query and nothing more. This will be passed in directly to the Wikipedia search engine.",
},
{ role: "user" as const, content: input.question },
];
const chatCompletion = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: messages,
temperature: 0,
});
return chatCompletion.choices[0].message.content ?? "";
},
{ name: "generateWikiSearch" }
);
const retrieve = traceable(
async (input: { query: string; numDocuments: number }) => {
const { results } = await wiki.search(input.query, { limit: 10 });
const finalResults: Array<{
page_content: string;
type: "Document";
metadata: { url: string };
}> = [];
for (const result of results) {
if (finalResults.length >= input.numDocuments) {
// Just return the top 2 pages for now
break;
}
const page = await wiki.page(result.title, { autoSuggest: false });
const summary = await page.summary();
finalResults.push({
page_content: summary.extract,
type: "Document",
metadata: { url: page.fullurl },
});
}
return finalResults;
},
{ name: "retrieve", run_type: "retriever" }
);
const generateAnswer = traceable(
async (input: { question: string; context: string }) => {
const messages = [
{
role: "system" as const,
content: `Answer the user's question based only on the content below:\n\n${input.context}`,
},
{ role: "user" as const, content: input.question },
];
const chatCompletion = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: messages,
temperature: 0,
});
return chatCompletion.choices[0].message.content ?? "";
},
{ name: "generateAnswer" }
);
const ragPipeline = traceable(
async ({ question }: { question: string }, numDocuments: number = 2) => {
const query = await generateWikiSearch({ question });
const retrieverResults = await retrieve({ query, numDocuments });
const context = retrieverResults
.map((result) => result.page_content)
.join("\n\n");
const answer = await generateAnswer({ question, context });
return answer;
},
{ name: "ragPipeline" }
);
此管道将生成如下所示的追踪: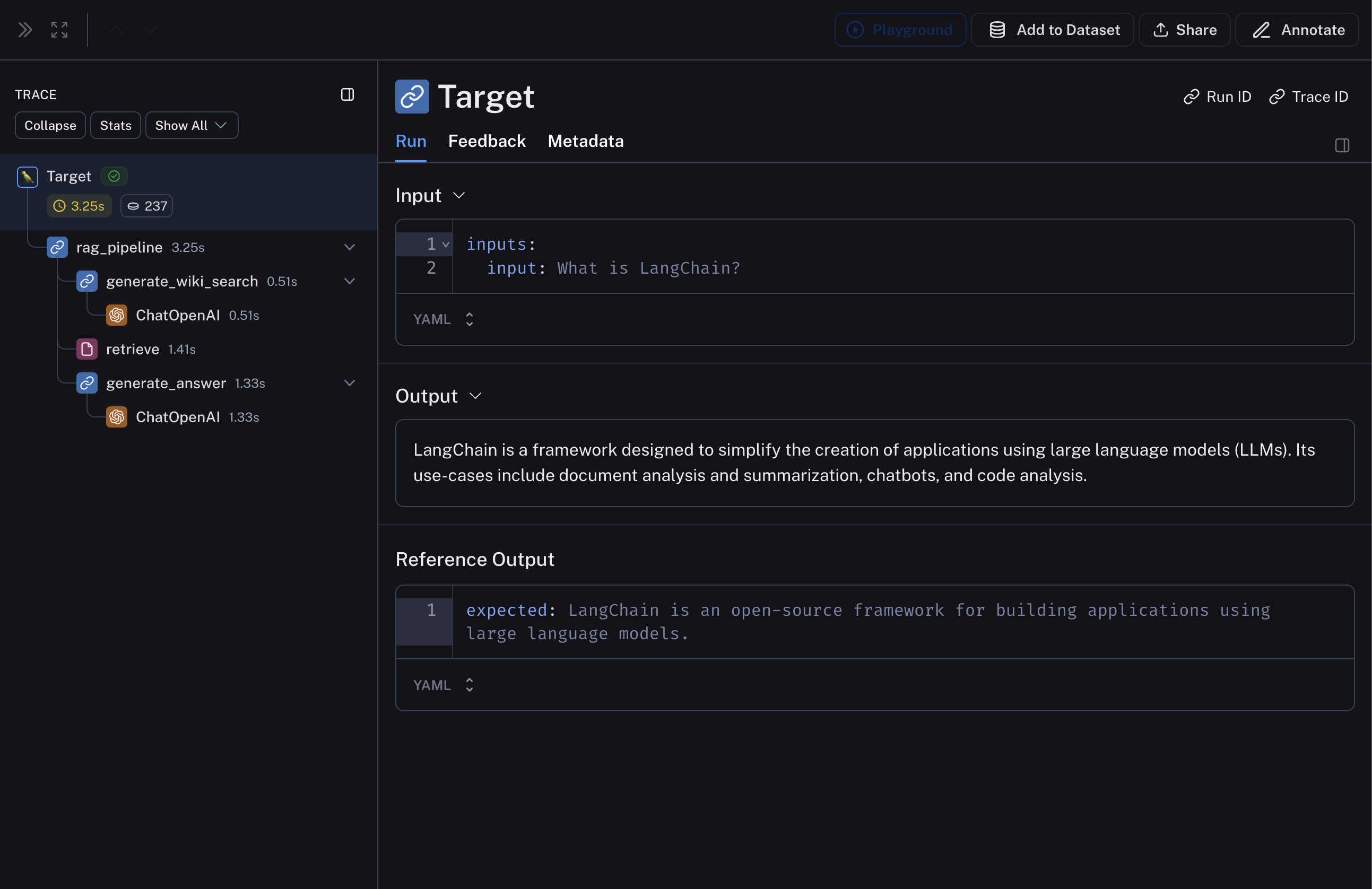
2. 创建数据集和示例以评估管道
我们正在构建一个非常简单的数据集,其中包含几个示例来评估管道。
- Python
- TypeScript
需要 langsmith>=0.3.13
from langsmith import Client
ls_client = Client()
dataset_name = "Wikipedia RAG"
if not ls_client.has_dataset(dataset_name=dataset_name):
dataset = ls_client.create_dataset(dataset_name=dataset_name)
examples = [
{"inputs": {"question": "What is LangChain?"}},
{"inputs": {"question": "What is LangSmith?"}},
]
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
import { Client } from "langsmith";
const client = new Client();
const examples = [
[
"What is LangChain?",
"LangChain is an open-source framework for building applications using large language models.",
],
[
"What is LangSmith?",
"LangSmith is an observability and evaluation tool for LLM products, built by LangChain Inc.",
],
];
const datasetName = "Wikipedia RAG";
const inputs = examples.map(([input, _]) => ({ input }));
const outputs = examples.map(([_, expected]) => ({ expected }));
const dataset = await client.createDataset(datasetName);
await client.createExamples({ datasetId: dataset.id, inputs, outputs });
3. 定义您的自定义评估器
如上所述,我们将定义两个评估器:一个评估检索到的文档与输入查询的相关性,另一个评估生成答案与检索到的文档的幻觉。我们将使用 LangChain LLM 封装器,以及 with_structured_output 来定义幻觉评估器。
这里的关键是评估器函数应该遍历 run / rootRun 参数以访问管道的中间步骤。然后评估器可以处理中间步骤的输入和输出,根据所需的标准进行评估。
- Python
- TypeScript
示例为方便起见使用 langchain,这不是必需的。
from langchain.chat_models import init_chat_model
from langsmith.schemas import Run
from pydantic import BaseModel, Field
def document_relevance(run: Run) -> bool:
"""Checks if retriever input exists in the retrieved docs."""
qa_pipeline_run = next(
r for run in run.child_runs if r.name == "qa_pipeline"
)
retrieve_run = next(
r for run in qa_pipeline_run.child_runs if r.name == "retrieve"
)
page_contents = "\n\n".join(
doc["page_content"] for doc in retrieve_run.outputs["output"]
)
return retrieve_run.inputs["query"] in page_contents
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
is_grounded: bool = Field(..., description="True if the answer is grounded in the facts, False otherwise.")
# LLM with structured outputs for grading hallucinations
# For more see: https://python.langchain.ac.cn/docs/how_to/structured_output/
grader_llm= init_chat_model("gpt-4o-mini", temperature=0).with_structured_output(
GradeHallucinations,
method="json_schema",
strict=True,
)
def no_hallucination(run: Run) -> bool:
"""Check if the answer is grounded in the documents.
Return True if there is no hallucination, False otherwise.
"""
# Get documents and answer
qa_pipeline_run = next(
r for r in run.child_runs if r.name == "qa_pipeline"
)
retrieve_run = next(
r for r in qa_pipeline_run.child_runs if r.name == "retrieve"
)
retrieved_content = "\n\n".join(
doc["page_content"] for doc in retrieve_run.outputs["output"]
)
# Construct prompt
instructions = (
"You are a grader assessing whether an LLM generation is grounded in / "
"supported by a set of retrieved facts. Give a binary score 1 or 0, "
"where 1 means that the answer is grounded in / supported by the set of facts."
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": f"Set of facts:\n{retrieved_content}\n\nLLM generation: {run.outputs['answer']}"},
]
grade = grader_llm.invoke(messages)
return grade.is_grounded
import { EvaluationResult } from "langsmith/evaluation";
import { Run, Example } from "langsmith/schemas";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { ChatOpenAI } from "@langchain/openai";
import { z } from "zod";
function findNestedRun(run: Run, search: (run: Run) => boolean): Run | null {
const queue: Run[] = [run];
while (queue.length > 0) {
const currentRun = queue.shift()!;
if (search(currentRun)) return currentRun;
queue.push(...currentRun.child_runs);
}
return null;
}
// A very simple evaluator that checks to see if the input of the retrieval step exists
// in the retrieved docs.
function documentRelevance(rootRun: Run, example: Example): EvaluationResult {
const retrieveRun = findNestedRun(rootRun, (run) => run.name === "retrieve");
const docs: Array<{ page_content: string }> | undefined =
retrieveRun.outputs?.outputs;
const pageContents = docs?.map((doc) => doc.page_content).join("\n\n");
const score = pageContents.includes(retrieveRun.inputs?.query);
return { key: "simple_document_relevance", score };
}
async function hallucination(
rootRun: Run,
example: Example
): Promise<EvaluationResult> {
const rag = findNestedRun(rootRun, (run) => run.name === "ragPipeline");
const retrieve = findNestedRun(rootRun, (run) => run.name === "retrieve");
const docs: Array<{ page_content: string }> | undefined =
retrieve.outputs?.outputs;
const documents = docs?.map((doc) => doc.page_content).join("\n\n");
const prompt = ChatPromptTemplate.fromMessages<{
documents: string;
generation: string;
}>([
[
"system",
[
`You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n`,
`Give a binary score 1 or 0, where 1 means that the answer is grounded in / supported by the set of facts.`,
].join("\n"),
],
[
"human",
"Set of facts: \n\n {documents} \n\n LLM generation: {generation}",
],
]);
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0,
}).withStructuredOutput(
z
.object({
binary_score: z
.number()
.describe("Answer is grounded in the facts, 1 or 0"),
})
.describe("Binary score for hallucination present in generation answer.")
);
const grader = prompt.pipe(llm);
const score = await grader.invoke({
documents,
generation: rag.outputs?.outputs,
});
return { key: "answer_hallucination", score: score.binary_score };
}
4. 评估管道
最后,我们将使用上面定义的自定义评估器运行 evaluate。
- Python
- TypeScript
def qa_wrapper(inputs: dict) -> dict:
"""Wrap the qa_pipeline so it can accept the Example.inputs dict as input."""
return {"answer": qa_pipeline(inputs["question"])}
experiment_results = ls_client.evaluate(
qa_wrapper,
data=dataset_name,
evaluators=[document_relevance, no_hallucination],
experiment_prefix="rag-wiki-oai"
)
import { evaluate } from "langsmith/evaluation";
await evaluate((inputs) => ragPipeline({ question: inputs.input }), {
data: datasetName,
evaluators: [hallucination, documentRelevance],
experimentPrefix: "rag-wiki-oai",
});
实验将包含评估结果,包括评估器的分数和评论: