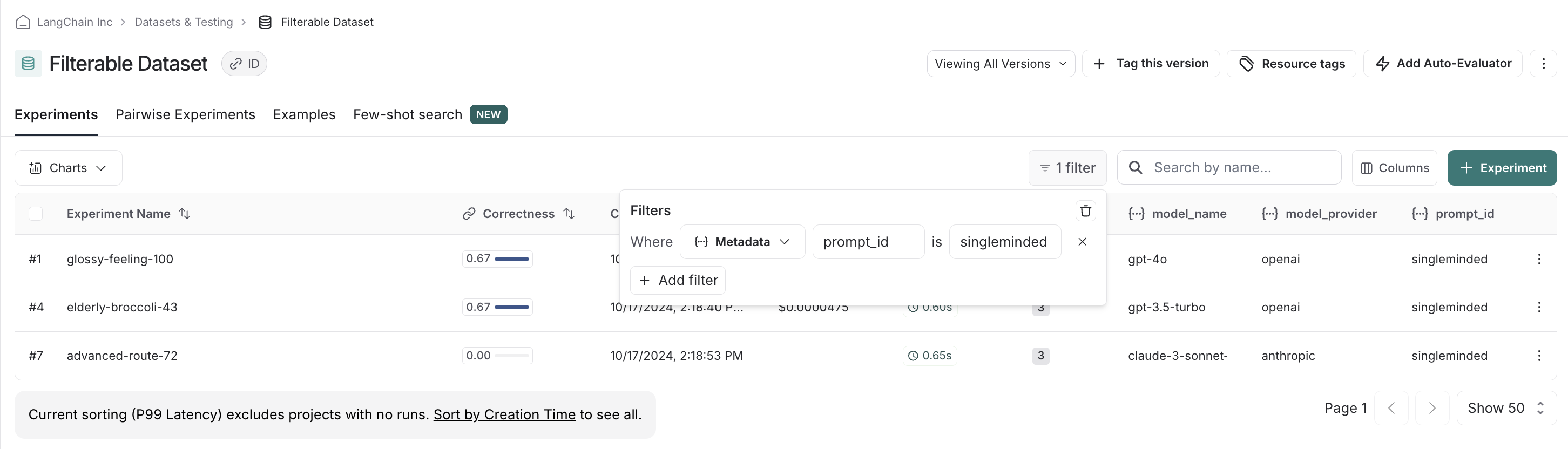
如何在 UI 中筛选实验
LangSmith 允许您根据反馈分数和元数据筛选先前的实验,以便轻松找到您关心的实验。
背景:为实验添加元数据
当您在 SDK 中运行实验时,您可以附加元数据,以便在 UI 中更轻松地进行筛选。如果您知道在运行实验时希望深入研究哪些维度,这将很有帮助。
在我们的示例中,我们将围绕使用的模型、模型提供商以及已知的提示 ID 为实验附加元数据。
- Python
models = {
"openai-gpt-4o": ChatOpenAI(model="gpt-4o", temperature=0),
"openai-gpt-4o-mini": ChatOpenAI(model="gpt-4o-mini", temperature=0),
"anthropic-claude-3-sonnet-20240229": ChatAnthropic(temperature=0, model_name="claude-3-sonnet-20240229")
}
prompts = {
"singleminded": "always answer questions with the word banana.",
"fruitminded": "always discuss fruit in your answers.",
"basic": "you are a chatbot."
}
def answer_evaluator(run, example) -> dict:
llm = ChatOpenAI(model="gpt-4o", temperature=0)
answer_grader = hub.pull("langchain-ai/rag-answer-vs-reference") | llm
score = answer_grader.invoke(
{
"question": example.inputs["question"],
"correct_answer": example.outputs["answer"],
"student_answer": run.outputs,
}
)
return {"key": "correctness", "score": score["Score"]}
dataset_name = "Filterable Dataset"
for model_type, model in models.items():
for prompt_type, prompt in prompts.items():
def predict(example):
return model.invoke(
[("system", prompt), ("user", example["question"])]
)
model_provider = model_type.split("-")[0]
model_name = model_type[len(model_provider) + 1:]
evaluate(
predict,
data=dataset_name,
evaluators=[answer_evaluator],
# ADD IN METADATA HERE!!
metadata={
"model_provider": model_provider,
"model_name": model_name,
"prompt_id": prompt_type
}
)
在 UI 中筛选实验
在 UI 中,我们默认会看到所有已运行的实验。
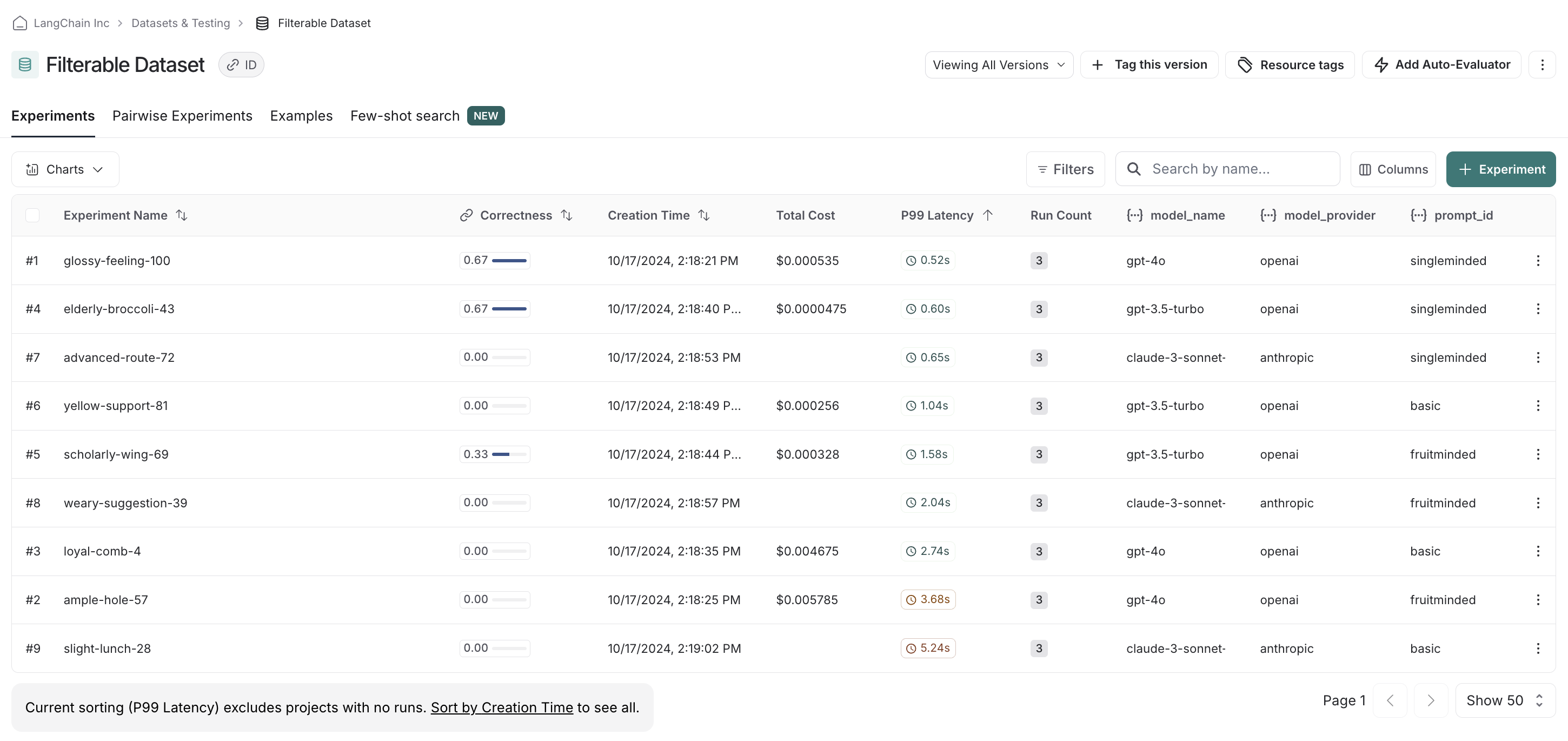
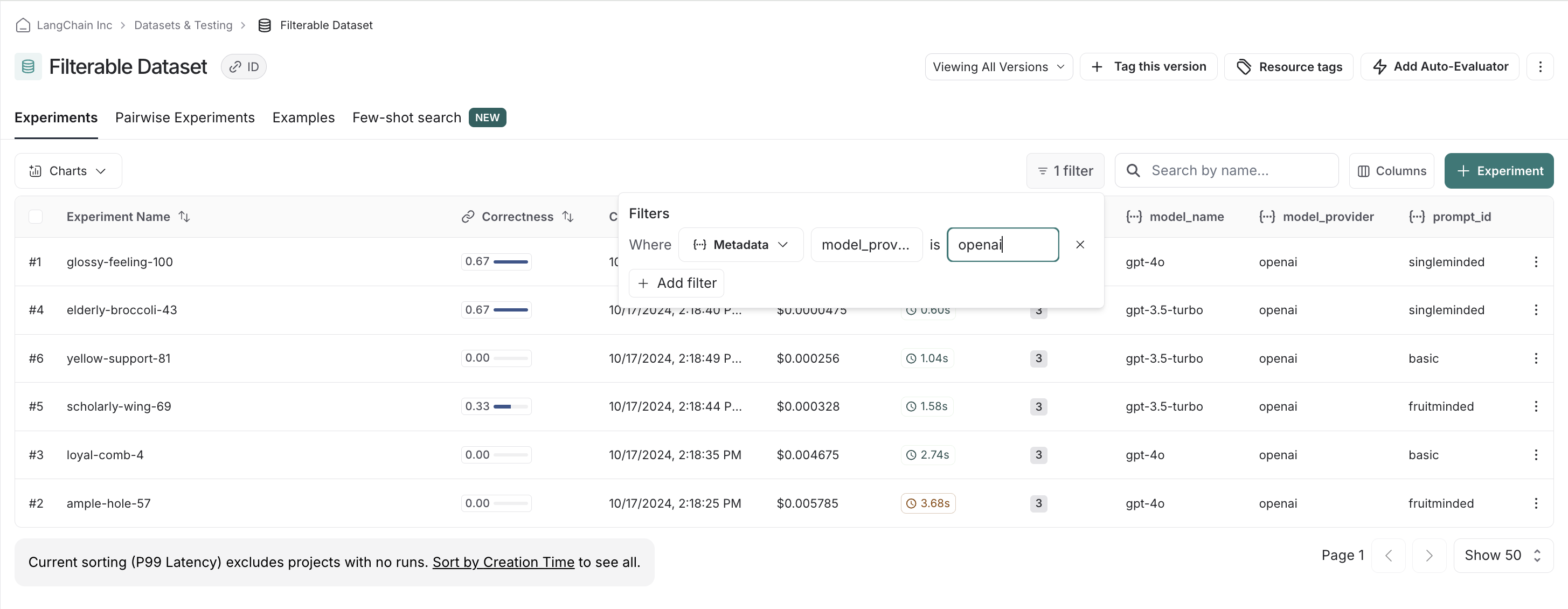
例如,如果我们偏爱 OpenAI 模型,我们可以轻松筛选并首先查看仅 OpenAI 模型中的分数。
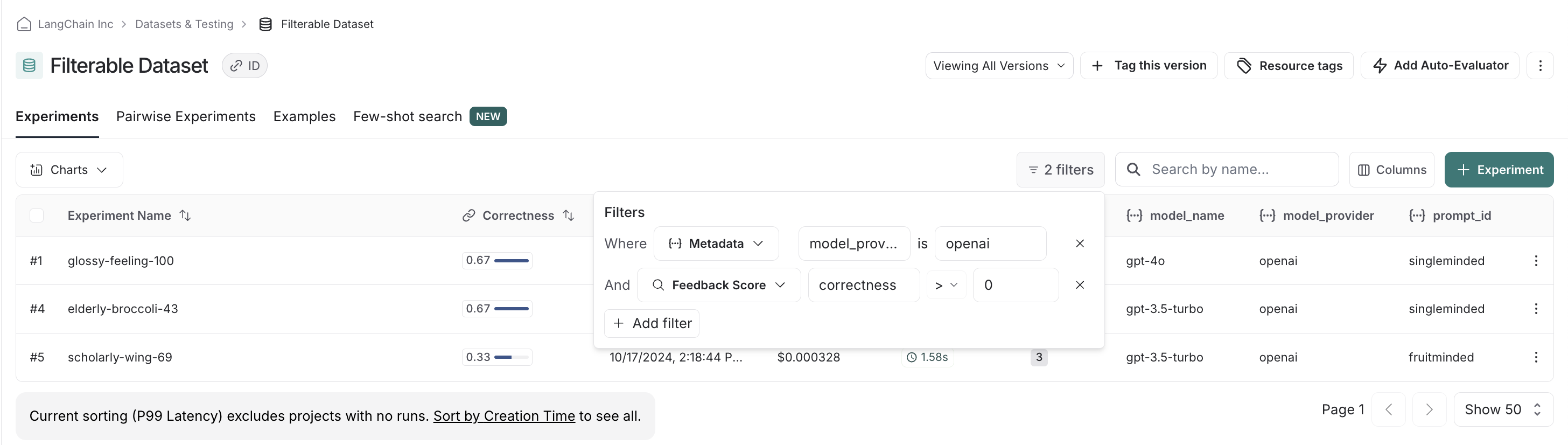
我们可以堆叠筛选器,从而筛选掉正确性低的分数,以确保我们只比较相关的实验。
最后,我们可以清除并重置筛选器。例如,如果我们看到使用 `singleminded` 提示词存在明确的赢家,我们可以更改筛选设置,看看其他模型提供商的模型是否也适用。