如何使用重复进行评估
运行多个重复可以更准确地估计您系统的性能,因为 LLM 输出是非确定性的。每次重复的输出可能不同。重复是减少易受高变异性影响的系统(例如代理)中噪声的一种方法。
在实验中配置重复
将可选的 num_repetitions 参数添加到 evaluate / aevaluate 函数(Python,TypeScript),以指定对数据集中每个示例评估的次数。例如,如果您的数据集中有 5 个示例,并将 num_repetitions 设置为 5,则每个示例将运行 5 次,总共 25 次运行。
- Python
- TypeScript
from langsmith import evaluate
results = evaluate(
lambda inputs: label_text(inputs["text"]),
data=dataset_name,
evaluators=[correct_label],
experiment_prefix="Toxic Queries",
num_repetitions=3,
)
import { evaluate } from "langsmith/evaluation";
await evaluate((inputs) => labelText(inputs["input"]), {
data: datasetName,
evaluators: [correctLabel],
experimentPrefix: "Toxic Queries",
numRepetitions=3,
});
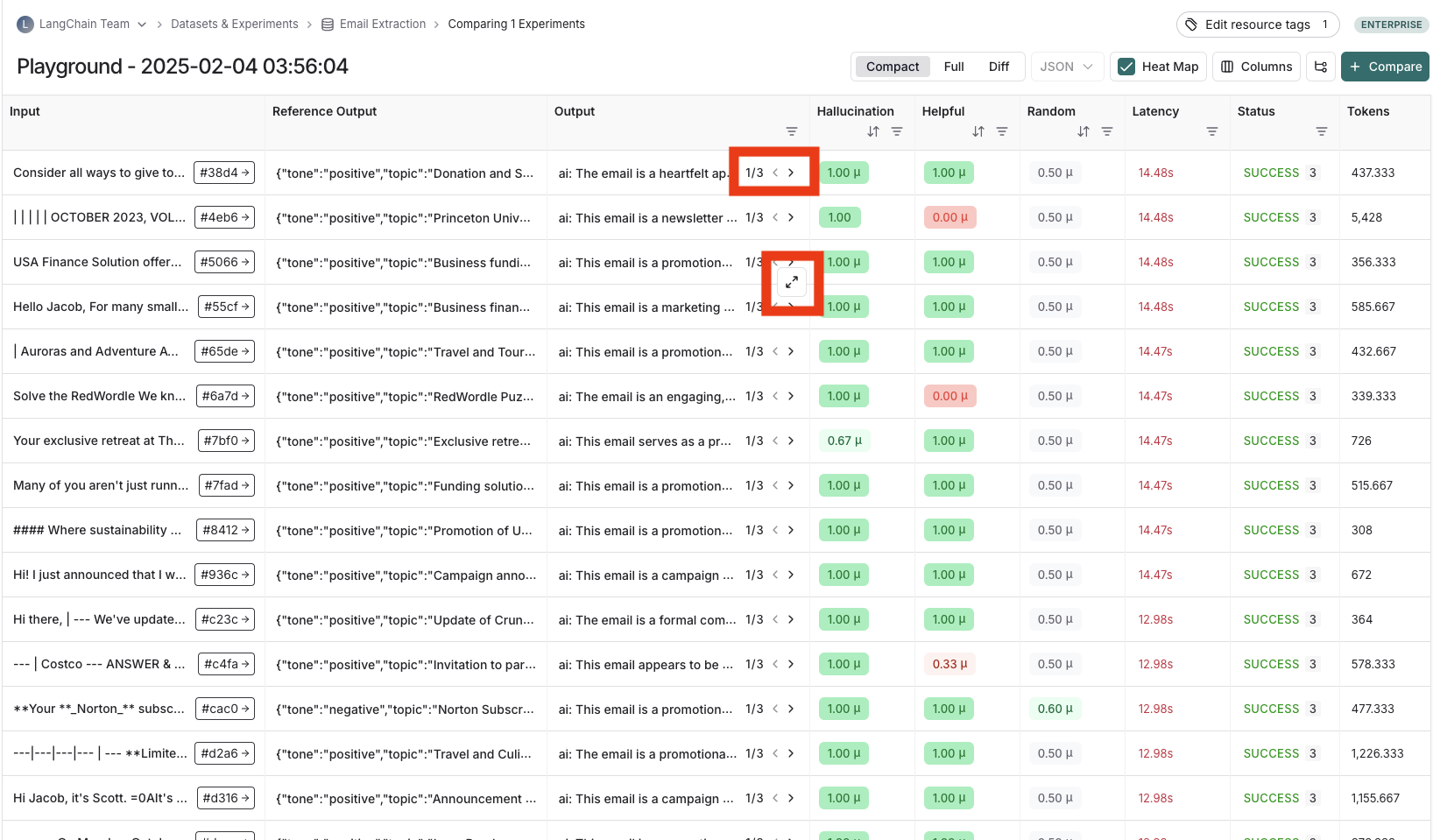
查看重复运行的实验结果
如果您使用重复运行了实验,输出结果列中将出现箭头,以便您可以在表格中查看输出。要查看每次重复的运行,请将鼠标悬停在输出单元格上并点击展开视图。当您使用重复运行实验时,LangSmith 会在表格中显示每个反馈分数的平均值。点击反馈分数可以查看单个运行的反馈分数,或查看重复运行的标准差。