计算基于Token的追踪成本
LangSmith 允许您追踪基于 Token 的 LLM 运行成本。这些成本将汇总到追踪和项目级别。
成本可以通过两种方式追踪
- 根据 Token 计数和模型价格推导
- 直接作为运行数据的一部分指定
在大多数情况下,将 Token 计数包含在运行数据中并在 LangSmith 中指定模型定价会更容易。LangSmith 假定成本与 Token 计数呈线性关系,并按 Token 类型细分。对于少数具有非线性定价的模型(例如,输入 Token 超过 X 个后,每个 Token 的价格会变化),我们建议在客户端计算成本并将其作为运行数据的一部分发送。
发送 Token 计数
为了让 LangSmith 准确地推导 LLM 运行的成本,您需要提供 Token 计数
- 如果您使用 LangSmith Python 或 TS/JS SDK 配合 OpenAI 或 Anthropic 模型,内置封装器将自动向 LangSmith 发送 Token 计数、模型提供商和模型名称数据。
- 如果您将 LangSmith SDK 与其他模型提供商一起使用,您应该仔细阅读本指南。
- 如果您使用 LangChain Python 或 TS/JS,对于大多数聊天模型集成,Token 计数、模型提供商和模型名称会自动发送到 LangSmith。如果某个聊天模型集成缺少 Token 计数,并且底层 API 在模型响应中包含 Token 计数,请在 LangChain 仓库中提交 GitHub issue。
如果未明确指定 Token 计数,LangSmith 将使用 tiktoken 估算 LLM 消息的 Token 计数。
指定模型名称
LangSmith 从运行元数据中的 ls_model_name 字段读取 LLM 模型名称。SDK 内置封装器和任何 LangChain 集成将自动为您处理此元数据指定。
设置模型价格
要从 Token 计数和模型名称计算成本,我们需要知道您正在使用的模型的每个 Token 的价格。LangSmith 有一个模型定价表。该表包含了大多数 OpenAI、Anthropic 和 Gemini 模型的定价信息。您可以添加其他模型的定价,或覆盖默认模型的定价。
您可以指定提示(输入)和完成(输出)Token 的价格。如果需要,您可以提供更详细的价格细分。例如,一些模型提供商对多模态或缓存的 Token 有不同的定价。
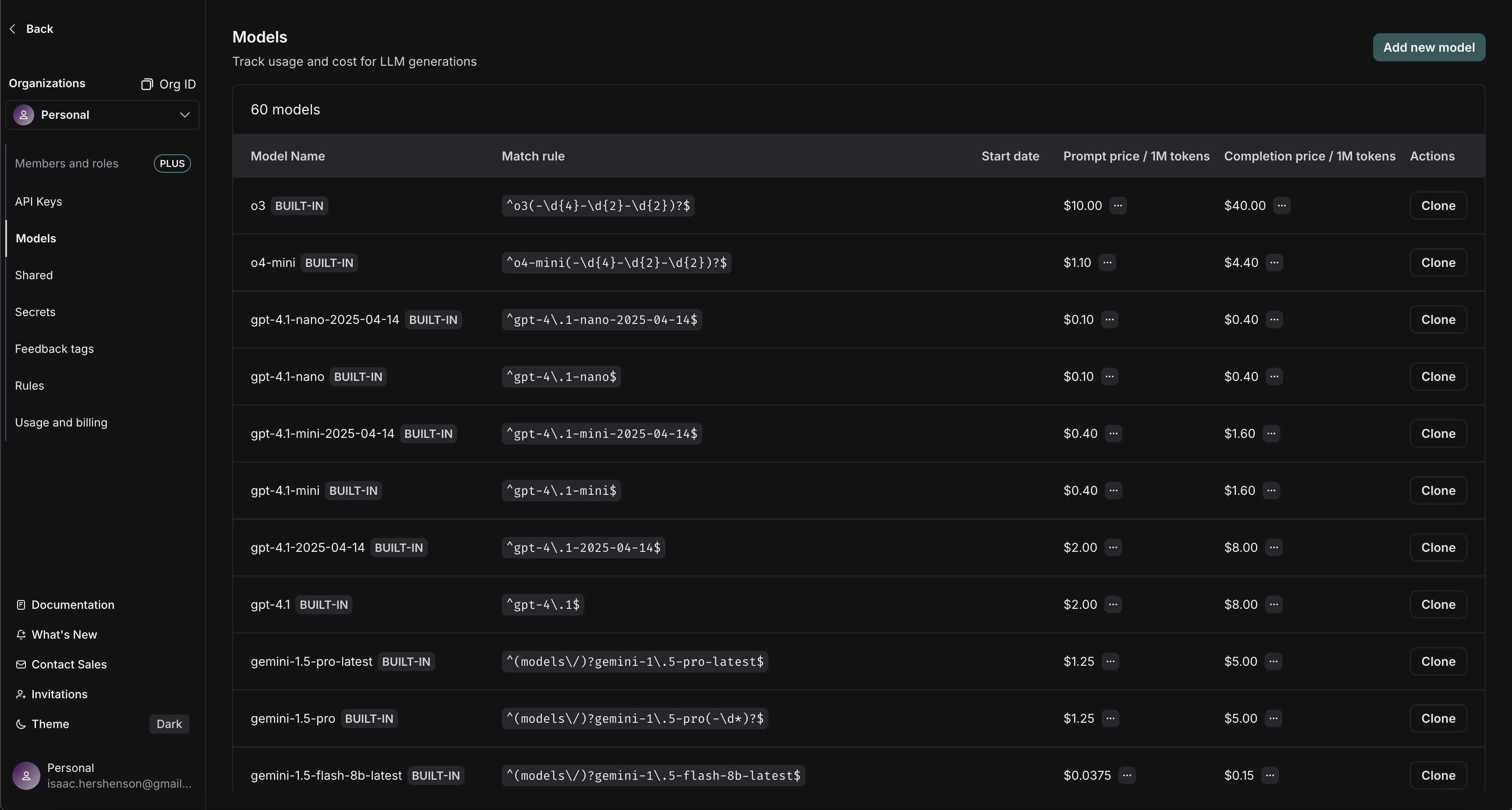
将鼠标悬停在提示/完成价格旁边的 ... 上,会显示按 Token 类型划分的价格细分。例如,您可以查看 audio 和 image 提示 Token 是否与默认文本提示 Token 的价格不同。
要在模型定价映射中创建新条目,请点击右上角的 Add new model 按钮。
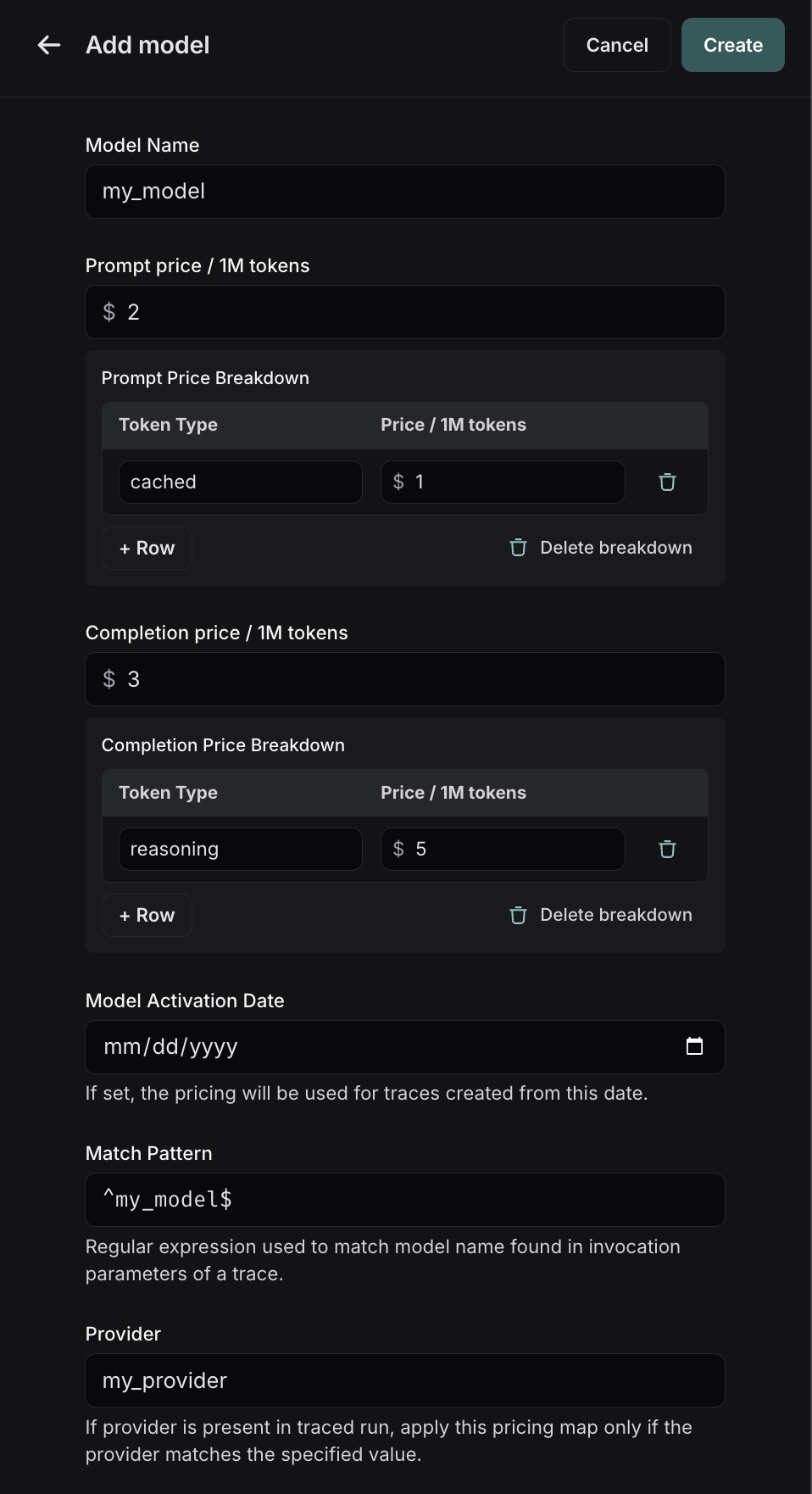
在这里,您可以指定以下字段
- 模型名称:模型的易读名称。
- 匹配模式:用于匹配模型名称的正则表达式模式。这用于匹配运行元数据中
ls_model_name的值。 - 提示(输入)价格:模型每 1M 输入 Token 的成本。此数字乘以提示中的 Token 数量,以计算提示成本。
- 完成(输出)价格:模型每 1M 输出 Token 的成本。此数字乘以完成中的 Token 数量,以计算完成成本。
- 提示(输入)价格细分(可选):每种不同类型提示 Token 的价格细分,例如
cache_read、video、audio等。 - 完成(输出)价格细分(可选):每种不同类型完成 Token 的价格细分,例如
reasoning、image等。 - 模型激活日期(可选):定价适用的日期。只有在此日期之后的运行才会应用此模型价格。
- 提供商(可选):模型的提供商。如果指定,这将与运行元数据中的
ls_provider进行匹配。
设置模型定价映射后,LangSmith 将根据 LLM 调用中提供的 Token 计数,自动计算并汇总追踪的基于 Token 的成本。
请注意,模型定价映射的更新将不会反映在已记录追踪的成本中。我们目前不支持回填模型定价更改。
对于指定定价细分,以下是 LangChain 聊天模型集成和 LangSmith SDK 封装器使用的详细 Token 计数类型
# Standardized
cache_read
cache_write
reasoning
audio
image
video
# Anthropic-only
ephemeral_1h_input_tokens
ephemeral_5m_input_tokens
成本公式
运行成本是根据从最具体到最不具体的 Token 类型贪婪计算的。假设我们将每 1M 提示 Token 的价格设置为 2 美元,其中每 1M cache_read 提示 Token 的详细价格为 1 美元,以及每 1M 完成 Token 的价格为 3 美元。如果我们上传以下使用元数据
{
"input_tokens": 20,
"input_token_details": {"cache_read": 5},
"output_tokens": 10,
"output_token_details": {},
"total_tokens": 30,
}
那么我们将按如下方式计算 Token 成本
# A.K.A. prompt_cost
# Notice that we compute the cache_read cost and then for any
# remaining input_tokens we apply the default input price.
input_cost = 5 * 1e-6 + (20 - 5) * 2e-6 # 3.5e-5
# A.K.A. completion_cost
output_cost = 10 * 3e-6 # 3e-5
total_cost = input_cost + output_cost # 6.5e-5
直接发送成本
如果您正在追踪返回 Token 成本信息的 LLM 调用,或者正在追踪采用非 Token 定价方案的 API,或者在运行时拥有准确的成本信息,您可以选择在追踪时填充一个 usage_metadata 字典,而不是依赖 LangSmith 的内置成本计算。
请参阅本指南,了解如何手动为运行提供成本信息。