为您的LLM应用程序添加可观测性
可观测性对于任何软件应用程序都非常重要,但对于LLM应用程序来说尤为如此。LLM本质上是非确定性的,这意味着它们可能产生意想不到的结果。这使得它们比一般的应用程序更难调试。
幸运的是,LangSmith可以提供帮助!LangSmith拥有LLM原生的可观测性,让您能够深入了解您的应用程序。
请注意,可观测性在应用程序开发的所有阶段都非常重要——从原型设计、内测到生产。在所有阶段都有不同的考量,但它们都紧密相连。在本教程中,我们将逐步讲解这一自然过程。
假设我们正在使用OpenAI SDK构建一个简单的RAG应用程序。我们要为其添加可观测性的简单应用程序看起来像这样:
- Python
- TypeScript
from openai import OpenAI
openai_client = OpenAI()
# This is the retriever we will use in RAG
# This is mocked out, but it could be anything we want
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
# This is the end-to-end RAG chain.
# It does a retrieval step then calls OpenAI
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs="\n".join(docs))
return openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
import { OpenAI } from "openai";
const openAIClient = new OpenAI();
// This is the retriever we will use in RAG
// This is mocked out, but it could be anything we want
async function retriever(query: string) {
return ["This is a document"];
}
// This is the end-to-end RAG chain.
// It does a retrieval step then calls OpenAI
async function rag(question: string) {
const docs = await retriever(question);
const systemMessage =
"Answer the users question using only the provided information below:\n\n" +
docs.join("\n");
return await openAIClient.chat.completions.create({
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: question },
],
model: "gpt-4o-mini",
});
}
原型设计
从一开始就设置好可观测性可以帮助您比以往
设置您的环境
首先,通过导航到设置页面创建一个API密钥。
接下来,安装LangSmith SDK
- Python SDK
- TypeScript SDK
pip install langsmith
npm install langsmith
最后,设置相应的环境变量。这将把跟踪记录到default项目(尽管您可以轻松更改)。
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY=<your-api-key>
export LANGSMITH_PROJECT=default
您可能会在其他地方看到这些变量被引用为LANGCHAIN_*。它们都是等效的,但最佳实践是使用LANGSMITH_TRACING、LANGSMITH_API_KEY、LANGSMITH_PROJECT。
LANGSMITH_PROJECT 标志仅在 JS SDK 版本 >= 0.2.16 中受支持,如果您使用的是旧版本,请改用 LANGCHAIN_PROJECT。
跟踪您的LLM调用
您可能想要跟踪的第一件事是您所有的OpenAI调用。毕竟,这是LLM实际被调用的地方,所以它是最重要的部分!我们已尝试通过引入一个极其简单的OpenAI包装器,使LangSmith尽可能简单地实现这一点。您所要做的就是修改您的代码,使其看起来像这样:
- Python
- TypeScript
from openai import OpenAI
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(OpenAI())
# This is the retriever we will use in RAG
# This is mocked out, but it could be anything we want
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
# This is the end-to-end RAG chain.
# It does a retrieval step then calls OpenAI
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs="\n".join(docs))
return openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
import { OpenAI } from "openai";
import { wrapOpenAI } from "langsmith/wrappers";
const openAIClient = wrapOpenAI(new OpenAI());
// This is the retriever we will use in RAG
// This is mocked out, but it could be anything we want
async function retriever(query: string) {
return ["This is a document"];
}
// This is the end-to-end RAG chain.
// It does a retrieval step then calls OpenAI
async function rag(question: string) {
const docs = await retriever(question);
const systemMessage =
"Answer the users question using only the provided information below:\n\n" +
docs.join("\n");
return await openAIClient.chat.completions.create({
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: question },
],
model: "gpt-4o-mini",
});
}
请注意我们如何导入from langsmith.wrappers import wrap_openai并使用它来包装OpenAI客户端 (openai_client = wrap_openai(OpenAI()))。
如果您以下列方式调用它会发生什么?
rag("where did harrison work")
这将只生成OpenAI调用的跟踪——它应该看起来像这样
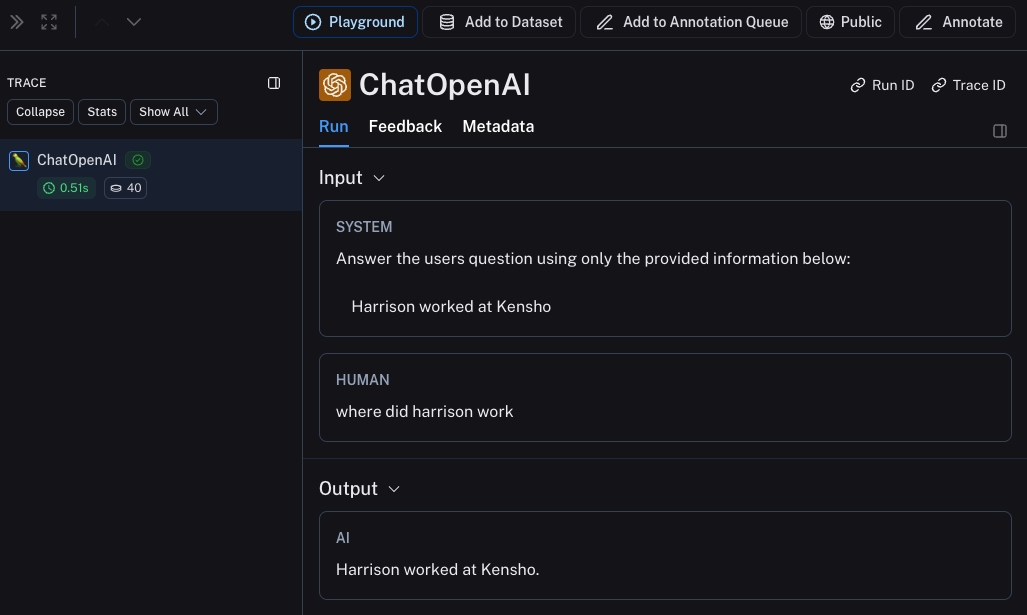
跟踪整个链条
很好——我们已经跟踪了LLM调用。但通常跟踪更多内容会非常有帮助。LangSmith正是为跟踪整个LLM管道而
- Python
- TypeScript
from openai import OpenAI
from langsmith import traceable
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(OpenAI())
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
@traceable
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs="\n".join(docs))
return openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
import { OpenAI } from "openai";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers";
const openAIClient = wrapOpenAI(new OpenAI());
async function retriever(query: string) {
return ["This is a document"];
}
const rag = traceable(async function rag(question: string) {
const docs = await retriever(question);
const systemMessage =
"Answer the users question using only the provided information below:\n\n" +
docs.join("\n");
return await openAIClient.chat.completions.create({
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: question },
],
model: "gpt-4o-mini",
});
});
请注意我们如何导入 from langsmith import traceable 并用它来装饰整个函数 (@traceable)。
如果您以下列方式调用它会发生什么?
rag("where did harrison work")
这将生成整个管道的跟踪(OpenAI 调用作为子运行)——它应该看起来像这样
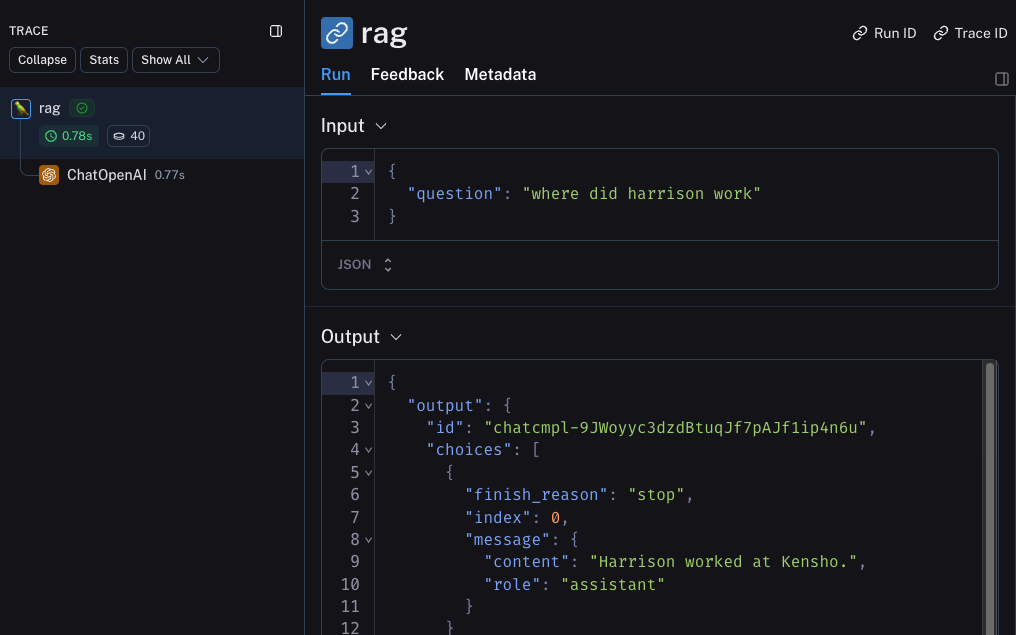
跟踪检索步骤
应用程序中还有一个我们尚未跟踪的部分——检索步骤!检索是LLM应用程序的关键部分,我们也简化了检索步骤的日志记录。我们只需要修改代码,使其看起来像这样:
- Python
- TypeScript
from openai import OpenAI
from langsmith import traceable
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(OpenAI())
@traceable(run_type="retriever")
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
@traceable
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs="\n".join(docs))
return openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
import { OpenAI } from "openai";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers";
const openAIClient = wrapOpenAI(new OpenAI());
const retriever = traceable(
async function retriever(query: string) {
return ["This is a document"];
},
{ run_type: "retriever" }
)
const rag = traceable(async function rag(question: string) {
const docs = await retriever(question);
const systemMessage =
"Answer the users question using only the provided information below:\n\n" +
docs.join("\n");
return await openAIClient.chat.completions.create({
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: question },
],
model: "gpt-4o-mini",
});
});
请注意我们如何导入from langsmith import traceable并用它来装饰整个函数 (@traceable(run_type="retriever"))。
如果您以下列方式调用它会发生什么?
rag("where did harrison work")
这将生成包含检索步骤的整个链条的跟踪——它应该看起来像这样
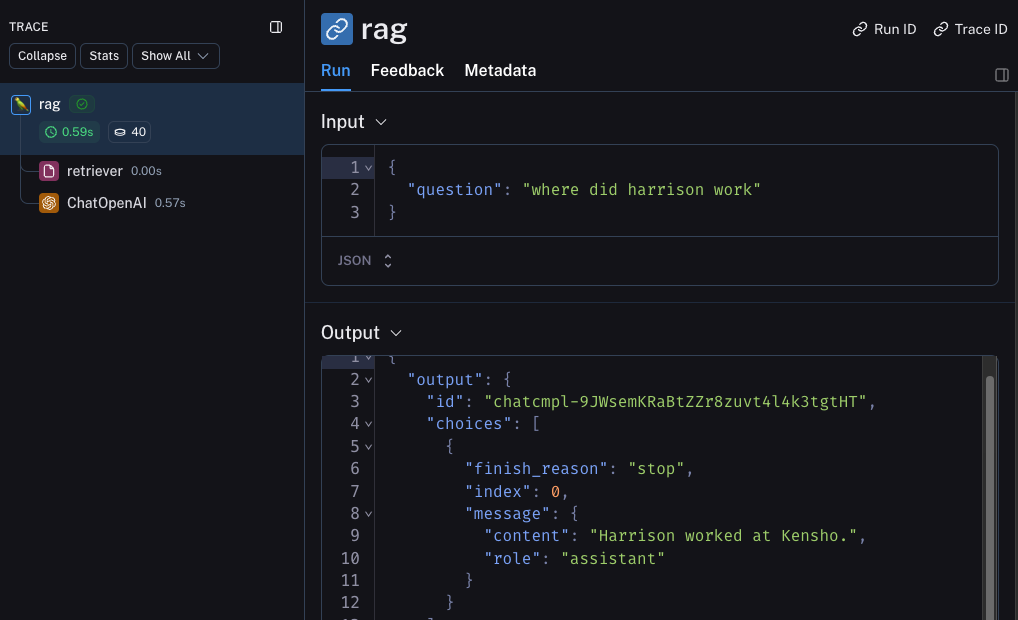
内测
LLM应用程序开发的下一个阶段是内测您的应用程序。这是您将其发布给一些初始用户的时候。在这里设置良好的可观测性至关重要,因为您通常不确切知道用户将如何实际使用您的应用程序,因此这使您能够深入了解他们的使用方式。这也意味着您可能需要对跟踪设置进行一些更改,以更好地适应这种情况。这扩展了您在上一节中设置的可观测性。
收集反馈
在内测阶段获得良好可观测性的重要组成部分是收集反馈。您收集的反馈通常是应用程序特有的——但至少一个简单的赞/踩是一个好的开始。记录反馈后,您需要能够轻松地将其与导致该反馈的运行关联起来。幸运的是,LangSmith可以轻松做到这一点。
首先,您需要从应用程序中记录反馈。一个简单的方法是为每次运行跟踪一个运行ID,然后使用该ID记录反馈。跟踪运行ID将看起来像这样:
import uuid
run_id = str(uuid.uuid4())
rag(
"where did harrison work",
langsmith_extra={"run_id": run_id}
)
将反馈与该运行关联起来将看起来像这样:
from langsmith import Client
ls_client = Client()
ls_client.create_feedback(
run_id,
key="user-score",
score=1.0,
)
一旦反馈被记录,您就可以在检查运行时点击Metadata选项卡,看到它与每次运行关联。它应该看起来像这样
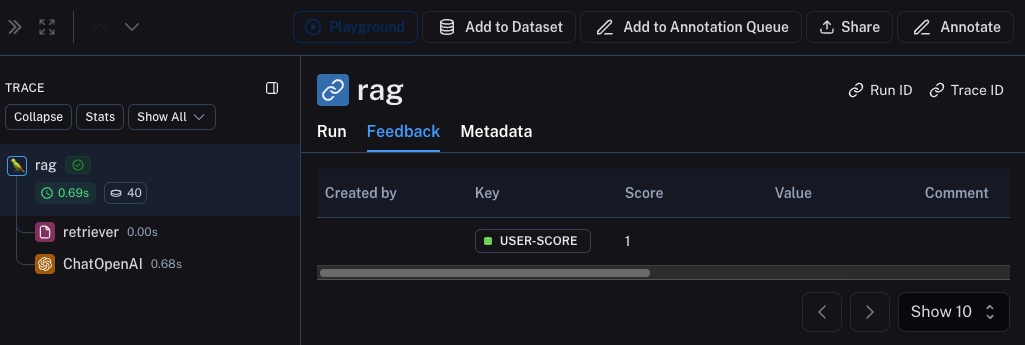
您还可以通过在运行表中应用过滤逻辑来查询所有带有正面(或负面)反馈的运行。您可以通过创建如下过滤器来完成此操作:
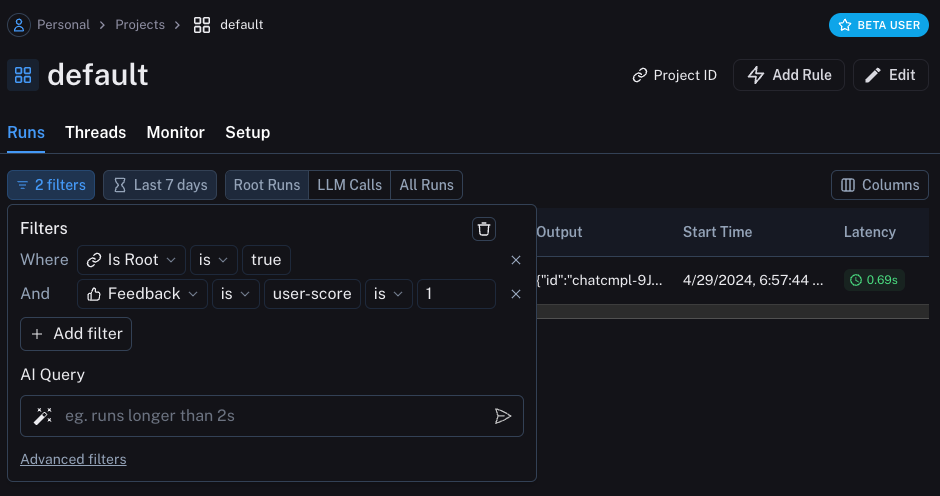
记录元数据
记录元数据也是个好主意。这让您可以开始跟踪应用程序的不同属性。这对于了解生成给定结果所使用的应用程序版本或变体非常重要。
在本例中,我们将记录使用的LLM。通常您可能会尝试不同的LLM,因此将该信息作为元数据对于过滤可能很有用。为此,我们可以像这样添加它:
from openai import OpenAI
from langsmith import traceable
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(OpenAI())
@traceable(run_type="retriever")
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
@traceable(metadata={"llm": "gpt-4o-mini"})
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs='\n'.join(docs))
return openai_client.chat.completions.create(messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": question},
], model="gpt-4o-mini")
请注意,我们在rag函数中添加了@traceable(metadata={"llm": "gpt-4o-mini"})。
以这种方式跟踪元数据假设它提前已知。这对于LLM类型来说没问题,但对于其他类型的信息——比如用户ID——则不太理想。为了记录这些信息,我们可以在运行时通过运行ID传递它。
import uuid
run_id = str(uuid.uuid4())
rag(
"where did harrison work",
langsmith_extra={"run_id": run_id, "metadata": {"user_id": "harrison"}}
)
现在我们已经记录了这两个元数据,我们应该能够在用户界面中这里看到它们都显示出来。

我们可以通过构建如下过滤器来过滤这些信息:
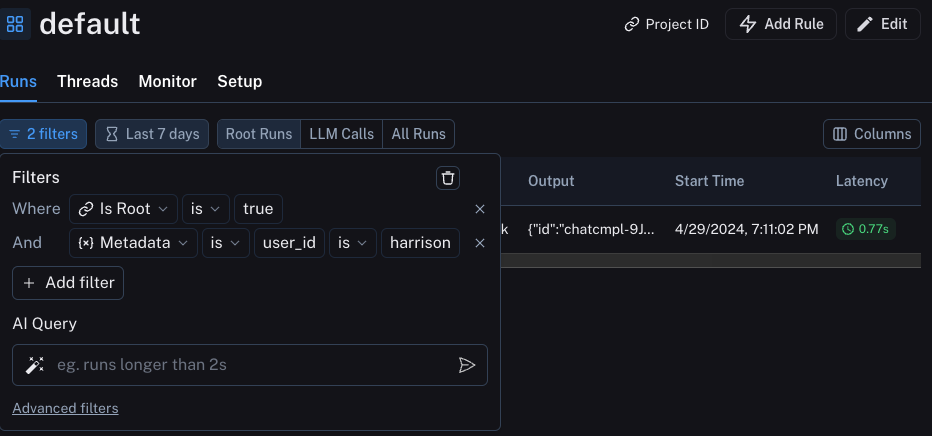
生产
太棒了——您已经利用这种新发现的可观测性快速迭代,并确信您的应用程序运行良好。是时候将其推向生产环境了!您需要添加哪些新的可观测性功能?
首先,请注意您已经添加的可观测性在生产中仍将持续提供价值。您将继续能够深入查看特定的运行。
在生产环境中,您可能会有大量的流量。因此,您可能不希望一次只查看一个数据点。幸运的是,LangSmith拥有一套工具来帮助生产环境中的可观测性。
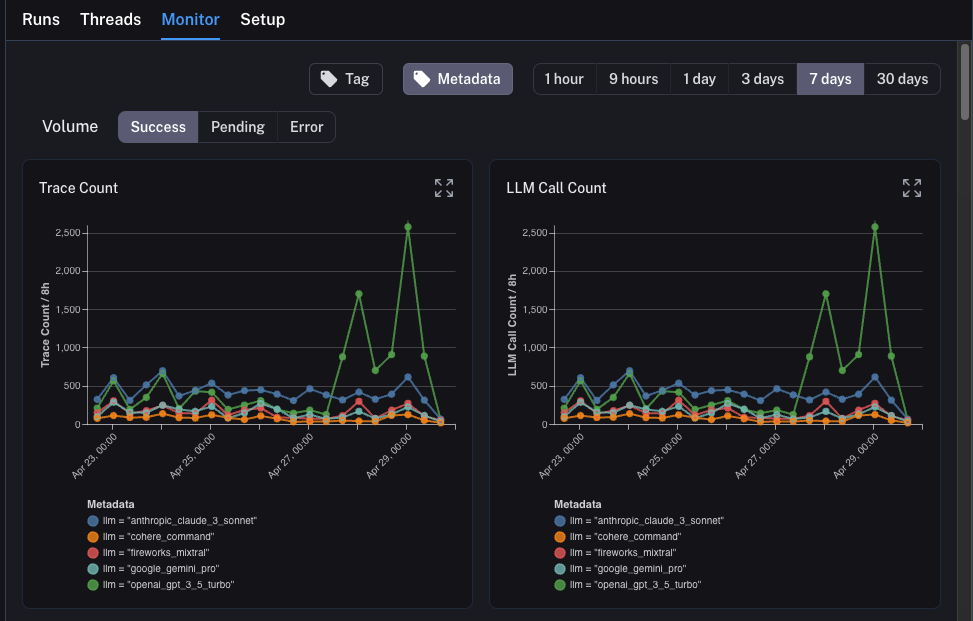
监控
如果您点击项目中的Monitor选项卡,您将看到一系列监控图表。在这里,我们跟踪许多LLM特定的统计数据——跟踪数量、反馈、首次token时间等。您可以在几个不同的时间段内查看这些数据。
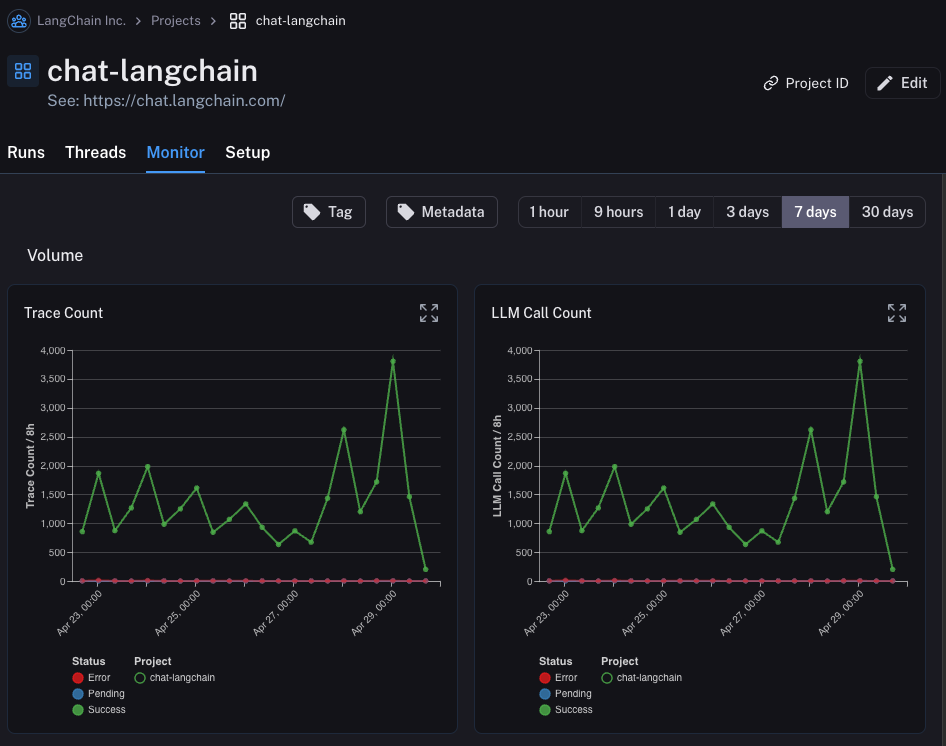
A/B 测试
A/B 测试的分组功能要求给定元数据键至少存在2个不同的值。
您还可以使用此选项卡执行一种A/B测试。在之前的教程中,我们开始跟踪了几个不同的元数据属性——其中一个是llm。我们可以根据
为了实现这一点,我们只需点击顶部的Metadata按钮。这将弹出一个下拉选项,供我们选择分组依据:
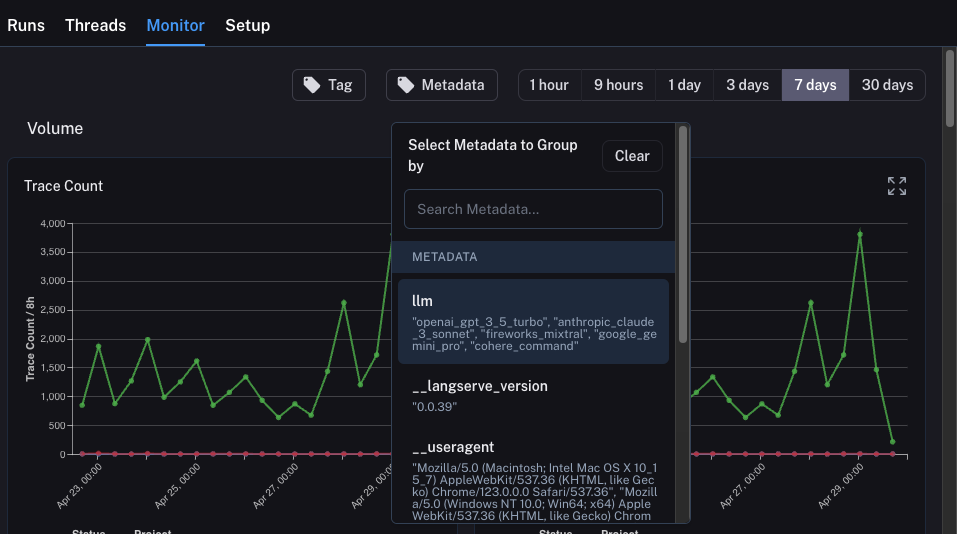
选择后,我们将开始看到按此属性分组的图表。
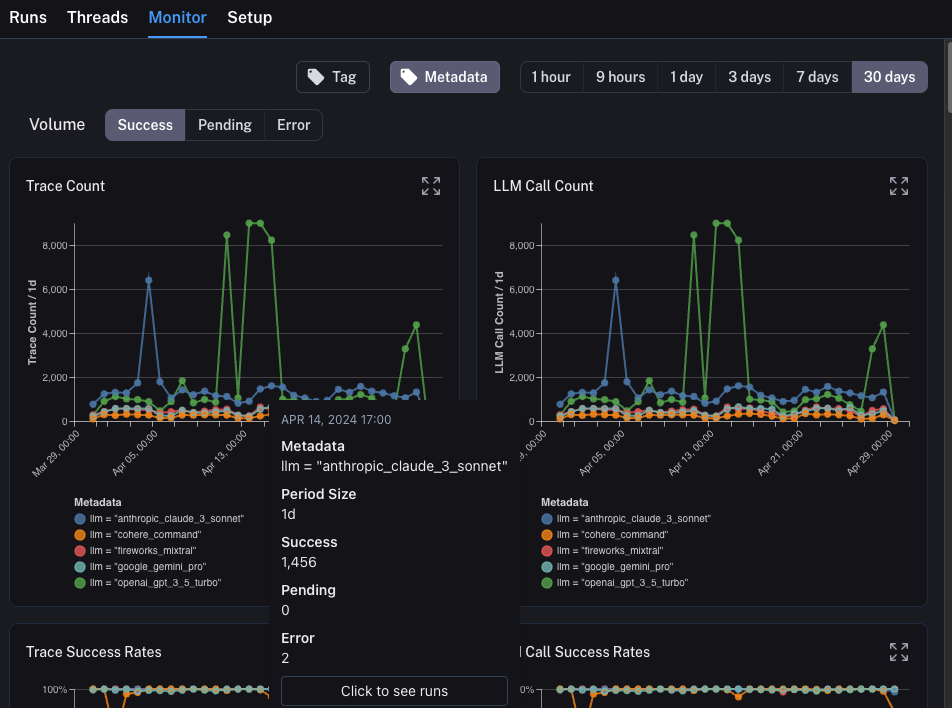
钻取
LangSmith提供的一个强大功能是,当您在查看监控图表时,能够轻松地深入研究您认为有问题的特定数据点。为此,您只需将鼠标悬停在监控图表中的数据点上。当您这样做时,您将能够点击该数据点。这将带您回到运行表,并显示一个过滤后的视图。
总结
在本教程中,您了解了如何为您的LLM应用程序设置一流的可观测性。无论您的应用程序处于哪个阶段,您都将从可观测性中受益。
如果您对可观测性有更深入的问题,请查阅操作指南部分,获取有关测试、提示管理等主题的指南。