在应用程序中筛选追踪
在深入了解此内容之前,阅读以下内容可能有助于您熟悉其中提及的概念
追踪项目可能包含大量数据。过滤器用于有效地导航和分析这些数据,使您能够
- 进行重点调查:快速缩小范围到特定运行以进行临时分析
- 调试和分析:识别并检查错误、失败的运行和性能瓶颈
本页包含一系列关于如何在追踪项目中筛选运行的指南。如果您通过 API 或 SDK 以编程方式导出运行进行分析,请参阅 导出追踪指南 以获取更多信息。
创建和应用过滤器
按运行属性筛选
在追踪项目中筛选运行有两种方式
- 过滤器:位于追踪项目页面左上方。您可以在此处构建和管理详细的过滤条件。
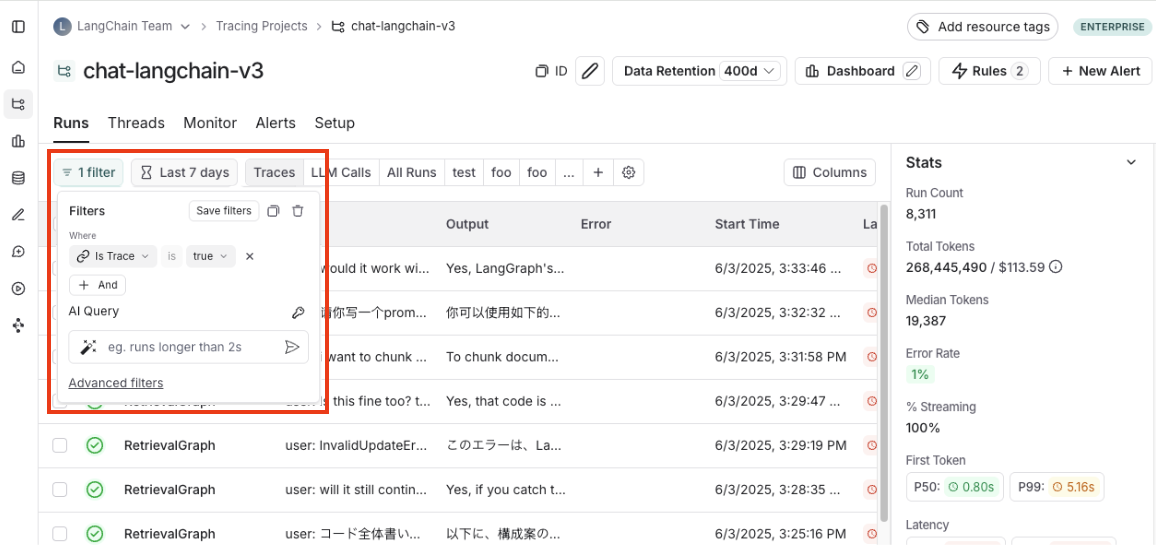
- 过滤器快捷方式:位于追踪项目页面的右侧边栏。过滤器快捷方式栏提供了根据项目中运行中最常出现的属性快速访问过滤器的方式。
默认情况下,应用了 IsTrace 为 true 的过滤器。这只显示顶层追踪。移除此过滤器将显示项目中的所有运行,包括中间 span。
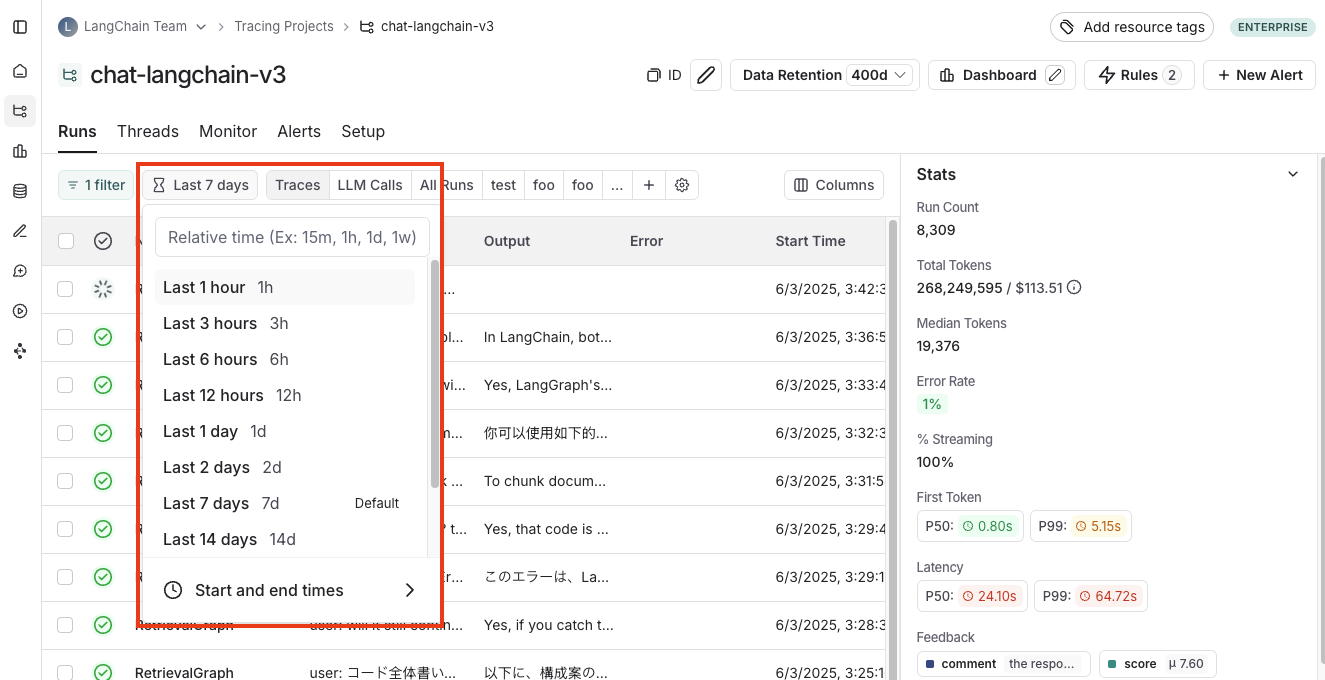
按时间范围筛选
除了按运行属性筛选外,您还可以按特定时间范围筛选运行。此选项位于追踪项目页面左上方。
过滤器操作符
可用的过滤器操作符取决于您正在筛选的属性的数据类型。以下是常见操作符的概述
- 是:精确匹配过滤器值
- 不是:与过滤器值负匹配
- 包含:对过滤器值进行部分匹配
- 不包含:对过滤器值进行负向部分匹配
- 是其中之一:匹配列表中任意一个值
>/<:适用于数值字段
特定筛选技术
筛选中间运行 (span)
为了筛选中间运行 (span),您首先需要移除默认的 IsTrace 为 true 的过滤器。例如,如果您想按子运行的 运行名称 或按 运行类型 进行筛选,就会这样做。
运行元数据和标签也是强大的筛选依据。这些依赖于您管道所有部分的良好标签。要了解更多信息,您可以查看本指南。
根据输入和输出筛选
您可以根据运行的输入和输出中的内容筛选运行。
要筛选输入或输出,您可以使用 全文搜索 过滤器,它将匹配任一字段中的关键词。对于更具针对性的搜索,您可以使用 输入 或 输出 过滤器,它们将仅根据各自的字段匹配内容。
您还可以指定多个匹配项,可以通过包含多个由空格分隔的术语,或者添加多个过滤器——这将尝试匹配所有提供的术语。
请注意,关键词搜索是通过分词并查找搜索关键词的任何部分匹配来完成的,因此不按特定顺序进行。我们从搜索中排除了常见的停用词(来自 nltk 停用词列表以及其他一些常见的 json 关键词)。
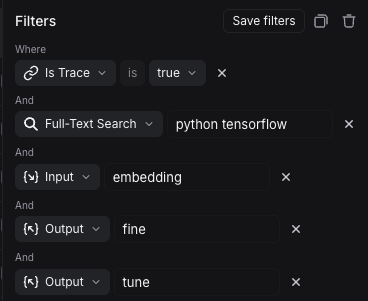
根据上述过滤器,系统将在输入或输出中搜索 python 和 tensorflow,并在输入中搜索 embedding,以及在输出中搜索 fine 和 tune。
根据输入/输出键值对筛选
除了全文搜索,您还可以根据输入和输出中特定的键值对筛选运行。这允许更精确的筛选,尤其是在处理结构化数据时。
要根据键值对进行筛选,请从过滤器下拉菜单中选择 输入键 或 输出键 过滤器。
例如,要匹配以下输入
{
"input": "What is the capital of France?"
}
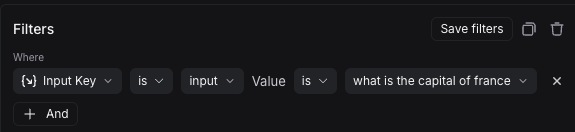
选择 过滤器,添加过滤器 以显示过滤选项。然后选择 输入键,输入 input 作为键,并输入 What is the capital of France? 作为值。
您还可以使用点表示法选择嵌套键名来匹配嵌套键。例如,要匹配输出中的嵌套键
{
"documents": [
{
"page_content": "The capital of France is Paris",
"metadata": {},
"type": "Document"
}
]
}
选择 输出键,输入 documents.page_content 作为键,并输入 The capital of France is Paris 作为值。这将匹配具有指定值的嵌套键 documents.page_content。

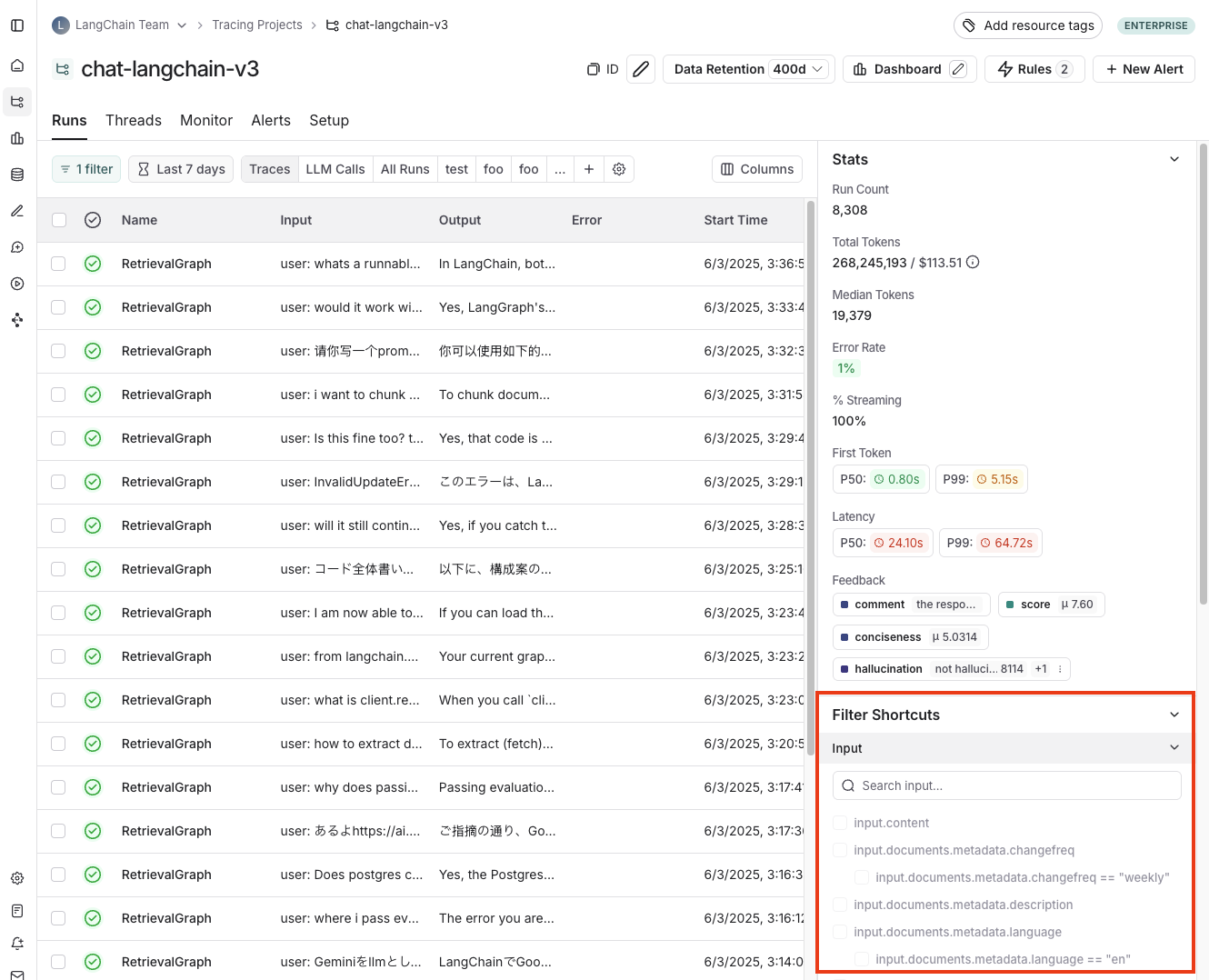
您可以添加多个键值过滤器来创建更复杂的查询。您还可以使用右侧的 过滤器快捷方式 根据常见的键值对快速筛选,如下所示
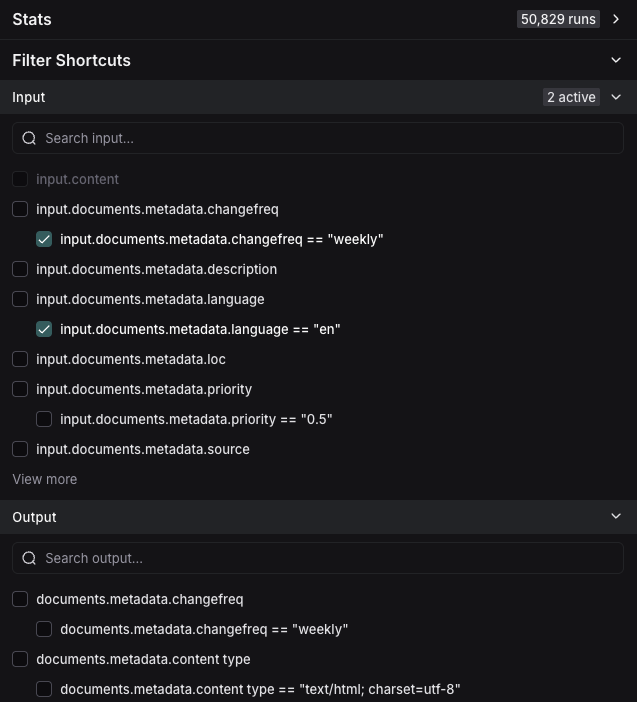
示例:筛选工具调用
通常需要搜索包含特定工具调用的追踪。工具调用通常在 LLM 运行的输出中显示。要筛选工具调用,您可以使用 输出键 过滤器。
虽然此示例将向您展示如何筛选工具调用,但同样的逻辑也可应用于筛选输出中的任何键值对。
在这种情况下,我们假设这是您要筛选的输出
{
"generations": [
[
{
"text": "",
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [],
"kwargs": {
"type": "ai",
"id": "run-ca7f7531-f4de-4790-9c3e-960be7f8b109",
"tool_calls": [
{
"name": "Plan",
"args": {
"steps": [
"Research LangGraph's node configuration capabilities",
"Investigate how to add a Python code execution node",
"Find an example or create a sample implementation of a code execution node"
]
},
"id": "toolu_01XexPzAVknT3gRmUB5PK5BP",
"type": "tool_call"
}
]
}
}
}
]
],
"llm_output": null,
"run": null,
"type": "LLMResult"
}
根据上面的示例,KV 搜索会将每个嵌套的 JSON 路径映射为键值对,供您搜索和筛选。
LangSmith 将其分解为以下可搜索的键值对集
| 键 | 值 |
|---|---|
generations.type | ChatGeneration |
generations.message.type | constructor |
generations.message.kwargs.type | ai |
generations.message.kwargs.id | run-ca7f7531-f4de-4790-9c3e-960be7f8b109 |
generations.message.kwargs.tool_calls.name | Plan |
generations.message.kwargs.tool_calls.args.steps | 研究 LangGraph 的节点配置功能 |
generations.message.kwargs.tool_calls.args.steps | 调查如何添加 Python 代码执行节点 |
generations.message.kwargs.tool_calls.args.steps | 查找或创建代码执行节点的示例实现 |
generations.message.kwargs.tool_calls.id | toolu_01XexPzAVknT3gRmUB5PK5BP |
generations.message.kwargs.tool_calls.type | tool_call |
type | LLMResult |
要搜索特定的工具调用,您可以使用以下输出键搜索,同时移除根运行过滤器
generations.message.kwargs.tool_calls.name = Plan
这将匹配 tool_calls 名称为 Plan 的根运行和非根运行。

键值对的负向筛选
不同类型的负向筛选可应用于 元数据、输入键 和 输出键 字段,以从结果中排除特定运行。
例如,要查找元数据键 phone 不等于 1234567890 的所有运行,请将 元数据 的 键 操作符设置为 是,键 字段设置为 phone,然后将 值 操作符设置为 不是,值 字段设置为 1234567890。这将匹配所有元数据键 phone 的值除了 1234567890 以外的任何运行。

要查找不包含特定元数据键的运行,请将 键 操作符设置为 不是。例如,将 键 操作符设置为 不是,并将 phone 作为键,将匹配所有元数据中没有 phone 字段的运行。
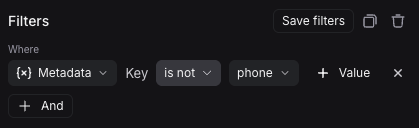
您还可以筛选既没有特定键也没有特定值的运行。要查找元数据中既没有键 phone 也没有任何值为 1234567890 的字段的运行,请将 键 操作符设置为 不是,键为 phone,并将 值 操作符设置为 不是,值为 1234567890。
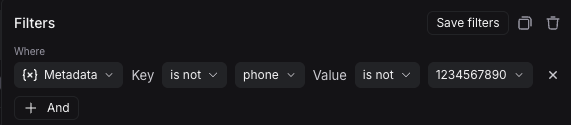
最后,您还可以筛选没有特定键但具有特定值的运行。要查找没有 phone 键但其他键的值为 1234567890 的运行,请将 键 操作符设置为 不是,键为 phone,并将 值 操作符设置为 是,值为 1234567890。
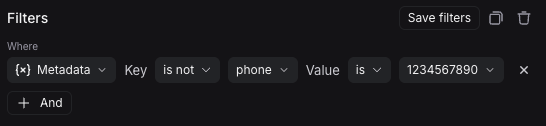
请注意,您可以使用 不包含 操作符代替 不是 来执行子字符串匹配。
保存过滤器
保存过滤器使您能够存储和重用常用过滤器配置。保存的过滤器特定于一个追踪项目。
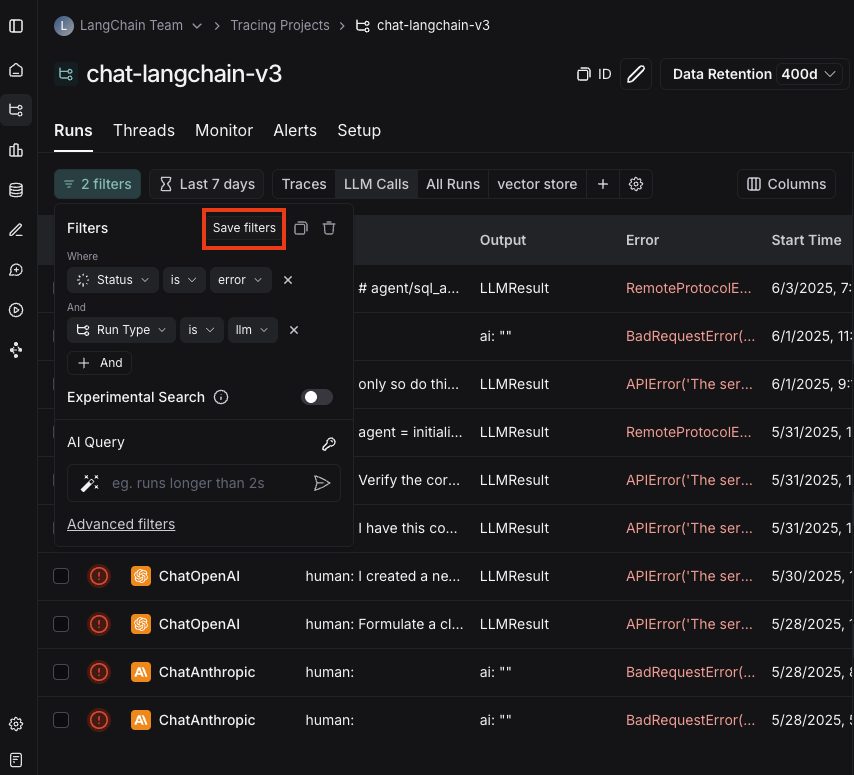
保存过滤器
在过滤器框中,在构建完过滤器后,点击保存过滤器按钮。这将弹出一个对话框,供您指定过滤器的名称和描述。
使用保存的过滤器
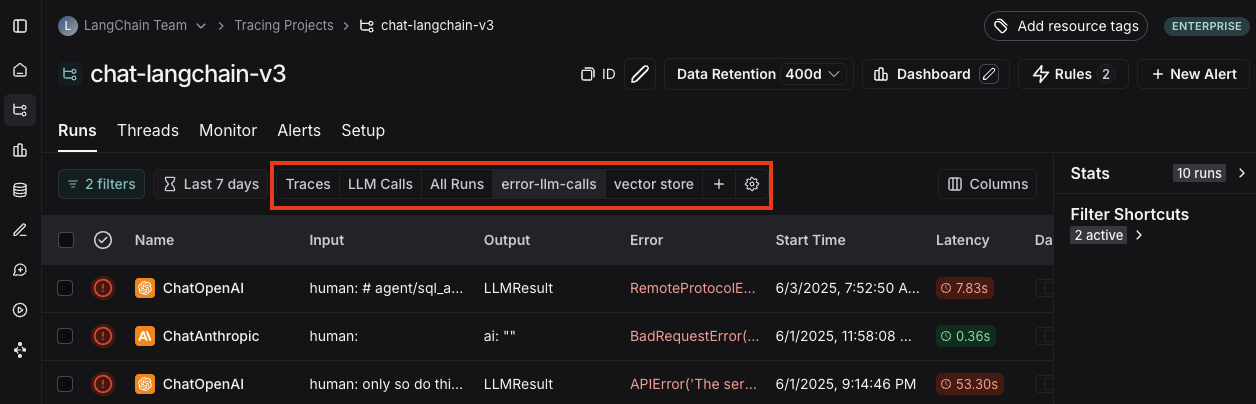
保存过滤器后,它将作为快速过滤器在过滤器栏中供您使用。如果您有三个以上保存的过滤器,将只直接显示两个,其余的可以通过“更多”菜单访问。您可以使用保存过滤器栏中的设置图标来选择性地隐藏默认保存的过滤器。
更新保存的过滤器
选中过滤器后,对过滤器参数进行任何更改。然后点击 更新过滤器 > 更新 来更新过滤器。
在同一菜单中,您还可以通过点击 更新过滤器 > 创建新过滤器 来创建一个新的保存过滤器。
删除保存的过滤器
点击保存过滤器栏中的设置图标,然后使用垃圾桶图标删除过滤器。
复制过滤器
您可以复制已构建的过滤器,以便与同事共享、稍后重用,或通过 API 或 SDK 以编程方式查询运行。
要复制过滤器,您可以先在 UI 中创建它。然后,您可以点击右上角的复制按钮。如果您已经构建了树或追踪过滤器,您也可以复制它们。
这将为您提供一个代表 LangSmith 查询语言中过滤器的字符串。例如:and(eq(is_root, true), and(eq(feedback_key, "user_score"), eq(feedback_score, 1)))。有关查询语言语法的更多信息,请参阅此参考。

在追踪视图中筛选运行
您还可以直接在追踪视图中应用过滤器,这对于筛选大量运行的追踪很有用。主运行表格视图中可用的相同过滤器也可以应用于此处。
默认情况下,只会显示匹配过滤器的运行。要在更广泛的追踪树上下文中查看匹配的运行,请将视图选项从“仅筛选”切换到“显示全部”或“最相关”。
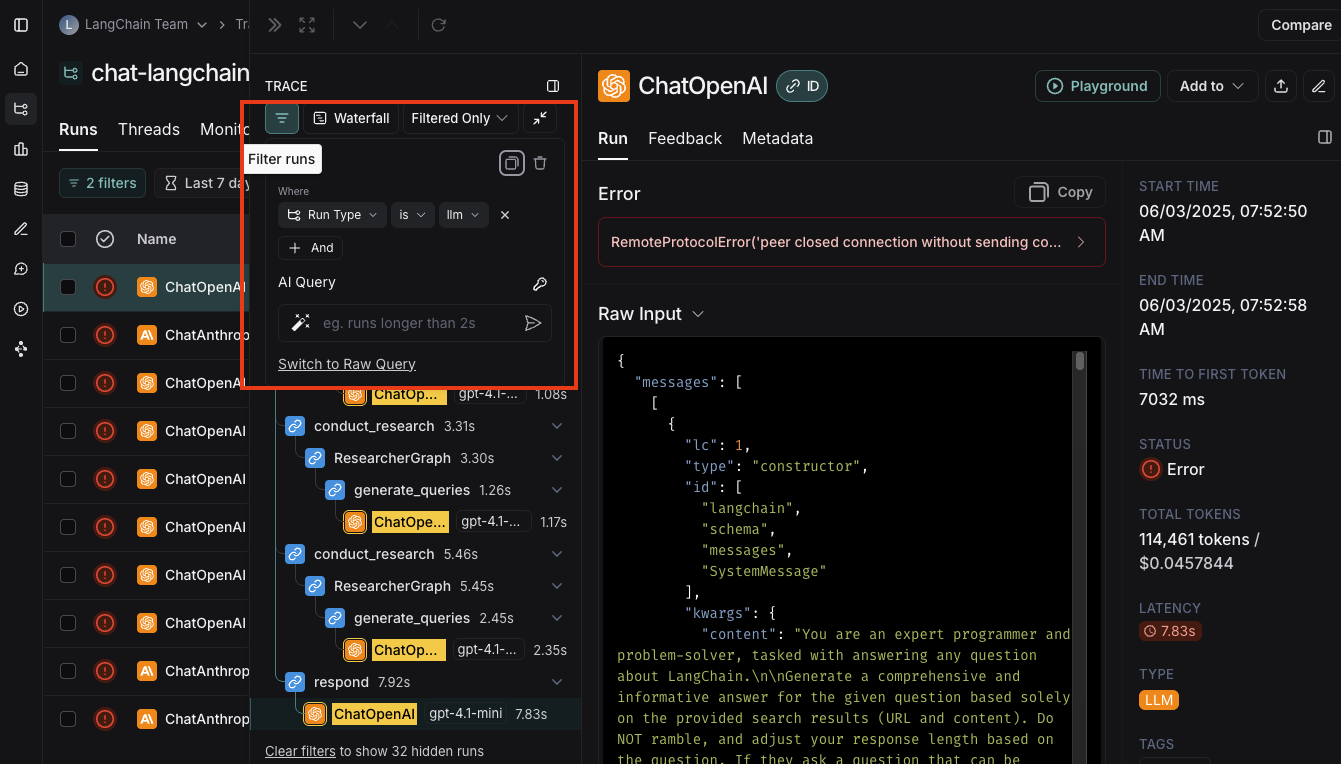
在 LangSmith 查询语言中手动指定原始查询
如果您已复制了先前构建的过滤器,您可能希望在将来的会话中手动应用此原始查询。
为此,您可以点击过滤器弹出框底部的 高级过滤器。然后您可以将原始查询粘贴到文本框中。
请注意,这将把该查询添加到现有查询中,而不是覆盖它。
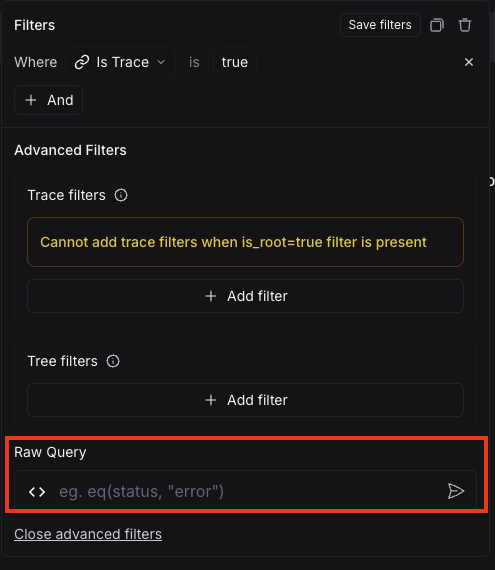
使用 AI 查询自动生成查询(实验性)
有时确定要指定的精确查询可能很困难!为了使其更容易,我们添加了 AI 查询 功能。有了它,您可以用自然语言输入您想构建的过滤器,它将将其转换为有效的查询。
例如:“所有运行时间超过 10 秒的运行”
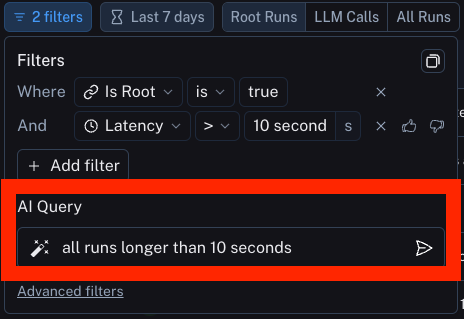
高级过滤器
根据根的属性筛选中间运行 (span)
一个常见的概念是筛选属于某个追踪的中间运行,该追踪的根运行具有某种属性。一个例子是筛选特定类型的中间运行,其根运行具有正向(或负向)反馈。
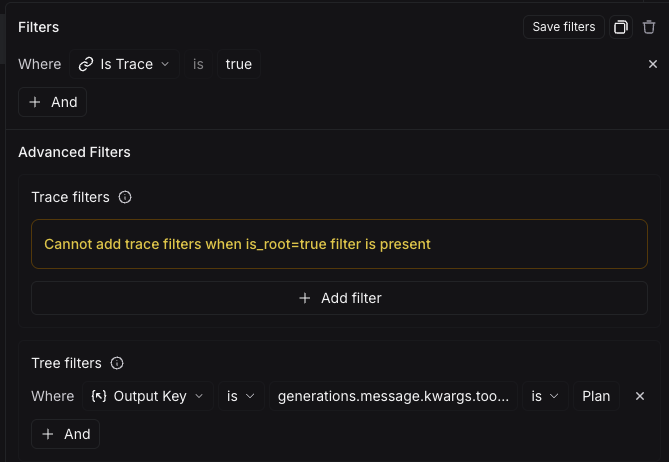
为此,首先设置一个中间运行过滤器(如上所述)。之后,您可以添加另一个过滤器规则。然后,您可以点击过滤器最底部的 高级过滤器 链接。这将打开一个新模态框,您可以在其中添加 追踪过滤器。这些过滤器将应用于您已经筛选出的各个运行的所有父运行的追踪。

筛选子运行具有某种属性的运行 (span)
这与上述情况相反。您可能希望搜索具有特定类型子运行的运行。一个例子是搜索所有包含名为 Foo 的子运行的追踪。这在 Foo 不总是被调用,但您想分析其被调用的情况时很有用。
为此,您可以点击过滤器最底部的 高级过滤器 链接。这将打开一个新的模态框,您可以在其中添加 树过滤器。这将使您指定的规则应用于您已经筛选出的各个运行的所有子运行。
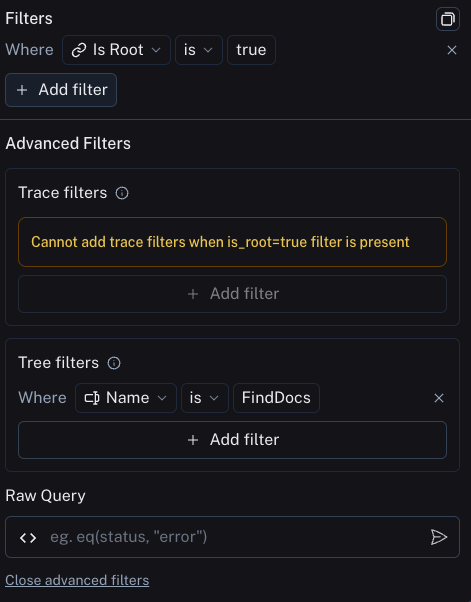
示例:筛选其树包含工具调用过滤器的所有运行
扩展上述工具调用筛选示例,如果您想筛选其树包含工具过滤器调用的所有运行,您可以在高级过滤器设置中使用树过滤器