设置在线评估
在线评估可为您生产环境中的追踪提供实时反馈。这有助于持续监控应用程序的性能——发现问题、衡量改进并确保长期质量一致性。
LangSmith 支持两种在线评估类型
- LLM 作为评判者: 使用 LLM 评估您的追踪。这是一种可扩展的方法,用于为您的输出提供类似人类的判断(例如,毒性、幻觉、正确性等)。
- 自定义代码: 直接在 LangSmith 中用 Python 编写评估器。常用于验证数据的结构或统计属性。
在线评估通过自动化规则进行配置。
开始使用在线评估器
1. 打开要配置在线评估器的追踪项目
2. 选择“添加规则”按钮(右上角)
3. 配置您的规则
- 添加评估器名称
- 您可以选择性地过滤要应用评估器的运行,或配置采样率。例如,通常会根据用户表示响应不满意、使用特定模型的运行等来应用特定的评估器。
- 选择 应用评估器
配置 LLM 作为评判者的在线评估器
查阅此指南以配置LLM 作为评判者的评估器。
配置自定义代码评估器
选择 自定义代码 评估器。
编写您的评估函数
自定义代码评估器限制。
允许的库: 您可以导入所有标准库函数,以及以下公共包
numpy (v2.2.2): "numpy"
pandas (v1.5.2): "pandas"
jsonschema (v4.21.1): "jsonschema"
scipy (v1.14.1): "scipy"
sklearn (v1.26.4): "scikit-learn"
网络访问: 您无法从自定义代码评估器访问互联网。
自定义代码评估器必须内联编写。我们建议在 LangSmith 中设置自定义代码评估器之前,先在本地进行测试。
在用户界面中,您会看到一个面板,允许您内联编写代码,并提供一些入门代码。
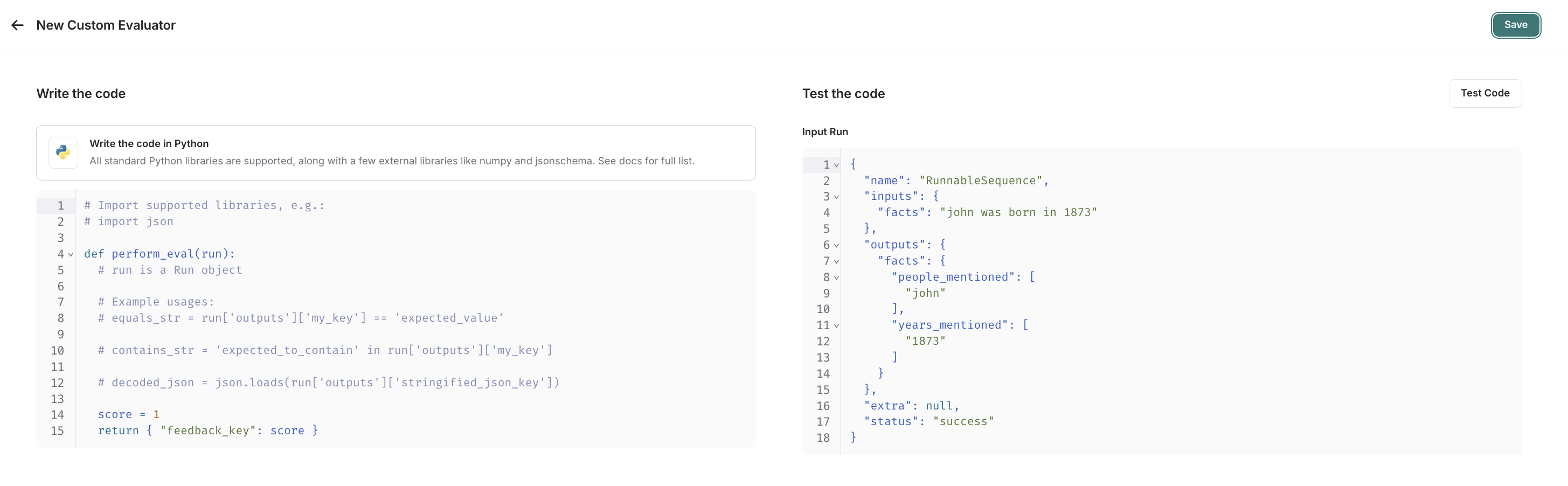
自定义代码评估器接受一个参数:
- 一个
Run(参考)。这表示用于评估的采样运行。
它们返回一个值:
- 反馈字典:一个字典,其键是您希望返回的反馈类型,值是您将为该反馈键提供的分数。例如,
{"correctness": 1, "silliness": 0}将在该运行上创建两种反馈,一种表示其正确,另一种表示其不荒谬。
在下面的截图中,您可以看到一个简单函数的示例,该函数验证实验中的每次运行都包含一个已知的 JSON 字段。
import json
def perform_eval(run):
output_to_validate = run['outputs']
is_valid_json = 0
# assert you can serialize/deserialize as json
try:
json.loads(json.dumps(output_to_validate))
except Exception as e:
return { "formatted": False }
# assert output facts exist
if "facts" not in output_to_validate:
return { "formatted": False }
# assert required fields exist
if "years_mentioned" not in output_to_validate["facts"]:
return { "formatted": False }
return {"formatted": True}
测试并保存您的评估函数
在保存之前,您可以通过点击 测试代码 来测试您的评估器函数在最近一次运行中的表现,以确保代码正确执行。
一旦您 保存,您的在线评估器将对新采样的运行(如果您选择了回填选项,则也包括回填的运行)进行评估。
如果您更喜欢视频教程,请查看 LangSmith 入门课程中的在线评估视频。